
Automating Cloudflare Tunnel with Terraform

Cloudflare Tunnel allows you to connect applications securely and quickly to Cloudflare’s edge. With Cloudflare Tunnel, teams can expose anything to the world, from internal subnets to containers, in a secure and fast way. Thanks to recent developments with our Terraform provider and the advent of Named Tunnels it’s never been easier to spin up.
Classic Tunnels to Named Tunnels
Historically, the biggest limitation to using Cloudflare Tunnel at scale was that the process to create a tunnel was manual. A user needed to download the binary for their OS, install/compile it, and then run the command cloudflared tunnel login. This would open a browser to their Cloudflare account so they could download a cert.pem file to authenticate their tunnel against Cloudflare’s edge with their account.
With the jump to Named Tunnels and a supported API endpoint Cloudflare users can automate this manual process. Named Tunnels also moved to allow a .json file for the origin side tunnel credentials instead of (or with) the cert.pem file. It has been a dream of mine since joining Cloudflare to write a Cloudflare Tunnel as code, along with my instance/application, and deploy it while I go walk my dog. Tooling should be easy to deploy and robust to use. That dream is now a reality and my dog could not be happier.

Okay, so what?
The ability to dynamically generate a tunnel and tie it into a back end application(s) brings several benefits to users including: putting more of their Cloudflare config in code, auto-scaling resources, dynamically spinning up resources such as bastion servers for secure logins, and saving time from avoiding manually generating/maintaining tunnels.
Tunnels also allow traffic to connect securely into Cloudflare’s edge for only the particular account they are affiliated with. In a world where IPs are increasingly ephemeral, tunnels allow for a modern approach to tying your application(s) into Cloudflare. Putting automation around tunnels allows teams to incorporate them into their existing CI/CD (continuous improvement/continuous development) pipelines.
Most importantly, the spin up of an environment securely tied into Cloudflare can be achieved with some Terraform config and then by running terraform apply. I can then go take my pup on an adventure while my environment kicks off.
Why Terraform?
While there are numerous Infrastructure as Code tools out there, Terraform has an actively maintained Cloudflare provider. This is not to say that this same functionality cannot be re-created by making use of the API endpoint with a tool of your choice. The overarching concepts here should translate quite nicely. Using Terraform we can deploy Cloudflare resources, origin resources, and configure our server all with one tool. Let’s see what setting that up looks like.
Terraform Config
The technical bits of this will cover how to set up an automated Named Tunnel that will proxy traffic to a Google compute instance (GCP) which is my backend for this example. These concepts should be the same regardless of where you host your applications such as an onprem location to a multi-cloud solution.
With Cloudflare Tunnel’s Ingress Rules, we can use a single tunnel to proxy traffic to a number of local services. In our case we will tie into a Docker container running HTTPbin and the local SSH daemon. These endpoints are being used to represent a standard login protocol (such as SSH or RDP) and an example web application (HTTPbin). We can even take it a step further by applying a Zero Trust framework with Cloudflare Access over the SSH hostname.
The version of Terraform used in this example is 0.15.0. Please refer to the provider documentation when using the Cloudflare Terraform provider. Tunnels are compatible with Terraform version 0.13+.
cdlg at cloudflare in ~/Documents/terraform/blog on master
$ terraform --version
Terraform v0.15.0
on darwin_amd64
+ provider registry.terraform.io/cloudflare/cloudflare v2.18.0
+ provider registry.terraform.io/hashicorp/google v3.56.0
+ provider registry.terraform.io/hashicorp/random v3.0.1
+ provider registry.terraform.io/hashicorp/template v2.2.0
Here is what the Terraform hierarchy looks like for this setup.
cdlg at cloudflare in ~/Documents/terraform/blog on master
$ tree .
.
├── README.md
├── access.tf
├── argo.tf
├── bootstrap.tf
├── instance.tf
├── server.tpl
├── terraform.tfstate
├── terraform.tfstate.backup
├── terraform.tfvars
├── terraform.tfvars.example
├── test.plan
└── versions.tf
0 directories, 12 files
We can ignore the files README.md and terraform.tfvars.example for now. The files ending in .tf is where our Terraform configuration lives. Each file is designated to a specific purpose. For example, the instance.tf file only contains the scope of the GCP server resources used with this deployment and the affiliated DNS records pointing to the tunnel on it.
cdlg at cloudflare in ~/Documents/terraform/blog on master
$ cat instance.tf
# Instance information
data "google_compute_image" "image" {
family = "ubuntu-minimal-1804-lts"
project = "ubuntu-os-cloud"
}
resource "google_compute_instance" "origin" {
name = "test"
machine_type = var.machine_type
zone = var.zone
tags = ["no-ssh"]
boot_disk {
initialize_params {
image = data.google_compute_image.image.self_link
}
}
network_interface {
network = "default"
access_config {
// Ephemeral IP
}
}
// Optional config to make instance ephemeral
scheduling {
preemptible = true
automatic_restart = false
}
metadata_startup_script = templatefile("./server.tpl",
{
web_zone = var.cloudflare_zone,
account = var.cloudflare_account_id,
tunnel_id = cloudflare_argo_tunnel.auto_tunnel.id,
tunnel_name = cloudflare_argo_tunnel.auto_tunnel.name,
secret = random_id.argo_secret.b64_std
})
}
# DNS settings to CNAME to tunnel target
resource "cloudflare_record" "http_app" {
zone_id = var.cloudflare_zone_id
name = var.cloudflare_zone
value = "${cloudflare_argo_tunnel.auto_tunnel.id}.cfargotunnel.com"
type = "CNAME"
proxied = true
}
resource "cloudflare_record" "ssh_app" {
zone_id = var.cloudflare_zone_id
name = "ssh"
value = "${cloudflare_argo_tunnel.auto_tunnel.id}.cfargotunnel.com"
type = "CNAME"
proxied = true
}
This is a personal preference — if desired, the entire Terraform config could be put into one file. One thing to note is the usage of variables throughout the files. For example, the value of var.cloudflare_zone is populated with the value provided to it from the terraform.tfvars file. This allows the configuration to be used as a template with other deployments. The only change that would be necessary is updating the relevant variables, such as in the terraform.tfvars file, when re-using the configuration.
When using a credentials file (vs environment variables such as a .tfvars file) it is very important that this file is exempted from the version tracking tool. With git this is accomplished with a .gitignore file. Before running this example the terraform.tfvars.example file is copied to terraform.tfvars within the same directory and filled in as needed. The .gitignore file is told to ignore any file named terraform.tfvars to exempt the actual variables from version tracking.
cdlg at cloudflare in ~/Documents/terraform/blog on master
$ cat .gitignore
# Local .terraform directories
**/.terraform/*
# .tfstate files
*.tfstate
*.tfstate.*
# Crash log files
crash.log
# Ignore any .tfvars files that are generated automatically for each Terraform run. Most
# .tfvars files are managed as part of configuration and so should be included in
# version control.
#
# example.tfvars
terraform.tfvars
# Ignore override files as they are usually used to override resources locally and so
# are not checked in
override.tf
override.tf.json
*_override.tf
*_override.tf.json
# Include override files you do wish to add to version control using negated pattern
#
# !example_override.tf
# Include tfplan files to ignore the plan output of command: terraform plan -out=tfplan
# example: *tfplan*
*tfplan*
*.plan*
*lock*
Now to the fun stuff! To create a Cloudflare Tunnel in Terraform we only need to set the following resources in our Terraform config (this is what populates the argo.tf file).
resource "random_id" "argo_secret" {
byte_length = 35
}
resource "cloudflare_argo_tunnel" "auto_tunnel" {
account_id = var.cloudflare_account_id
name = "zero_trust_ssh_http"
secret = random_id.argo_secret.b64_std
}
That’s it.
Technically you could get away with just the cloudflare_argo_tunnel resource, but using the random_id resource helps with not having to hard code the secret for the tunnel. Instead we can dynamically generate a secret for our tunnel each time we run Terraform.
Let’s break down what is happening in the cloudflare_argo_tunnel resource: we are passing the Cloudflare account ID (via the var.cloudflare_account_id variable), a name for our tunnel, and the dynamically generated secret for the tunnel, which is pulled from the random_id resource. Tunnels expect the secret to be in base64 standard encoding and at least 32 characters.
Using Named Tunnels now gives customers a UUID (universal unique identity) target to tie their applications to. These endpoints are routed off an internal domain to Cloudflare and can only be used with zones in your account, as mentioned earlier. This means that one tunnel can proxy multiple applications for various zones in your account, thanks to Cloudflare Tunnel Ingress Rules.
Now that we have a target for our services, we can create a tunnel/applications in the GCP instance. Terraform has a feature called a templatefile function that allows you to pass input variables as local variables (i.e. what the server can use to configure things) to an argument called metadata_startup_script.
resource "google_compute_instance" "origin" {
...
metadata_startup_script = templatefile("./server.tpl",
{
web_zone = var.cloudflare_zone,
account = var.cloudflare_account_id,
tunnel_id = cloudflare_argo_tunnel.auto_tunnel.id,
tunnel_name = cloudflare_argo_tunnel.auto_tunnel.name,
secret = random_id.argo_secret.b64_std
})
}
This abbreviated section of the google_compute_instance resource shows a templatefile using 5 variables passed to the file located at ./server.tpl. The file server.tpl is a bash script within the local directory that will configure the newly created GCP instance.
As indicated earlier, Named Tunnels can make use of a JSON credentials file instead of the historic use of a cert.pem file. By using a templatefile function pointing to a bash script (or cloud-init, etc…) we can dynamically generate the fields that populate both the cert.json file and the config.yml file used for Ingress Rules on the server/host. Then the bash script can install cloudflared as a system service, so it is persistent (i.e it can come back up after the machine is rebooted). Here is an example of this.
wget https://bin.equinox.io/c/VdrWdbjqyF/cloudflared-stable-linux-amd64.deb
sudo dpkg -i cloudflared-stable-linux-amd64.deb
mkdir ~/.cloudflared
touch ~/.cloudflared/cert.json
touch ~/.cloudflared/config.yml
cat > ~/.cloudflared/cert.json << "EOF"
{
"AccountTag" : "${account}",
"TunnelID" : "${tunnel_id}",
"TunnelName" : "${tunnel_name}",
"TunnelSecret" : "${secret}"
}
EOF
cat > ~/.cloudflared/config.yml << "EOF"
tunnel: ${tunnel_id}
credentials-file: /etc/cloudflared/cert.json
logfile: /var/log/cloudflared.log
loglevel: info
ingress:
- hostname: ${web_zone}
service: http://localhost:8080
- hostname: ssh.${web_zone}
service: ssh://localhost:22
- hostname: "*"
service: hello-world
EOF
sudo cloudflared service install
sudo cp -via ~/.cloudflared/cert.json /etc/cloudflared/
cd /tmp
sudo docker-compose up -d && sudo service cloudflared start
In this example, a heredoc is used to fill in the variable fields for the cert.json file and another heredoc is used to fill in the config.yml (Ingress Rules) file with the variables we set in Terraform. Taking a quick look at the cert.json file we can see that the Account ID is provided to it which secures the tunnel to your specific account. The UUID of the tunnel is then passed in along with the name that was assigned in the tunnel’s name argument. Lastly the 35 character secret is then passed to the tunnel. These are the necessary parameters to get our tunnel spun up against Cloudflare’s edge.
The config.yml file is where we set up the Ingress Rules for the Cloudflare Tunnel. The first few lines tell the tunnel which UUID to attach to, where the credentials are on the OS, and where the tunnel should write logs to. The log level of info is good for general use but for troubleshooting debug may be needed.
Next the first – hostname: line says any requests bound for that particular hostname need to be proxied to the service (HTTPbin) running at localhost port 8080. Following that the SSH target is defined and will proxy requests to the local SSH port. The next hostname is interesting in that we have a wildcard character. This functionality allows other zones or hostnames on the Account to point to the tunnel without being explicitly defined in Ingress Rules. The service that will respond to these requests is a built in hello world service the tunnel provides.
Pretty neat, but what else can we do? We can block all inbound networking to the server and instead use Cloudflare Tunnel to proxy the connections to Cloudflare’s edge. To safeguard the SSH hostname an Access policy can be applied over it.
SSH and Zero Trust
The Access team has several tutorials on how to tie your policies into Terraform. Using this as a guide we can create the Access related Terraform resources for the SSH endpoint.
# Access policy to apply zero trust policy over SSH endpoint
resource "cloudflare_access_application" "ssh_app" {
zone_id = var.cloudflare_zone_id
name = "Access protection for ssh.${var.cloudflare_zone}"
domain = "ssh.${var.cloudflare_zone}"
session_duration = "1h"
}
resource "cloudflare_access_policy" "ssh_policy" {
application_id = cloudflare_access_application.ssh_app.id
zone_id = var.cloudflare_zone_id
name = "Example Policy for ssh.${var.cloudflare_zone}"
precedence = "1"
decision = "allow"
include {
email = [var.cloudflare_email]
}
}
In the above cloudflare_access_application resource, a variable, var.cloudflare_zone_id, is used to pull in the Cloudflare Zone’s ID based on the value of the variable provided in the terraform.tfvars file. The Zone Name is also dynamically populated at runtime in the var.cloudflare_zone fields based on the value provided in the terraform.tfvars file. We also limit the scope of this access policy to ssh.targetdomain.com using the domain argument in the cloudflare_access_application resource.
In the cloudflare_access_policy resource, we take the information provided by the cloudflare_access_application resource called ssh_app and apply it as an active policy. The scope of who is allowed to log into this endpoint is the user’s email as provided by the var.cloudflare_email variable.
Terraform Spin up and SSH Connection
Now to connect to this SSH endpoint. First we need to spin up our environment. This can be done with terraform plan and then terraform apply.
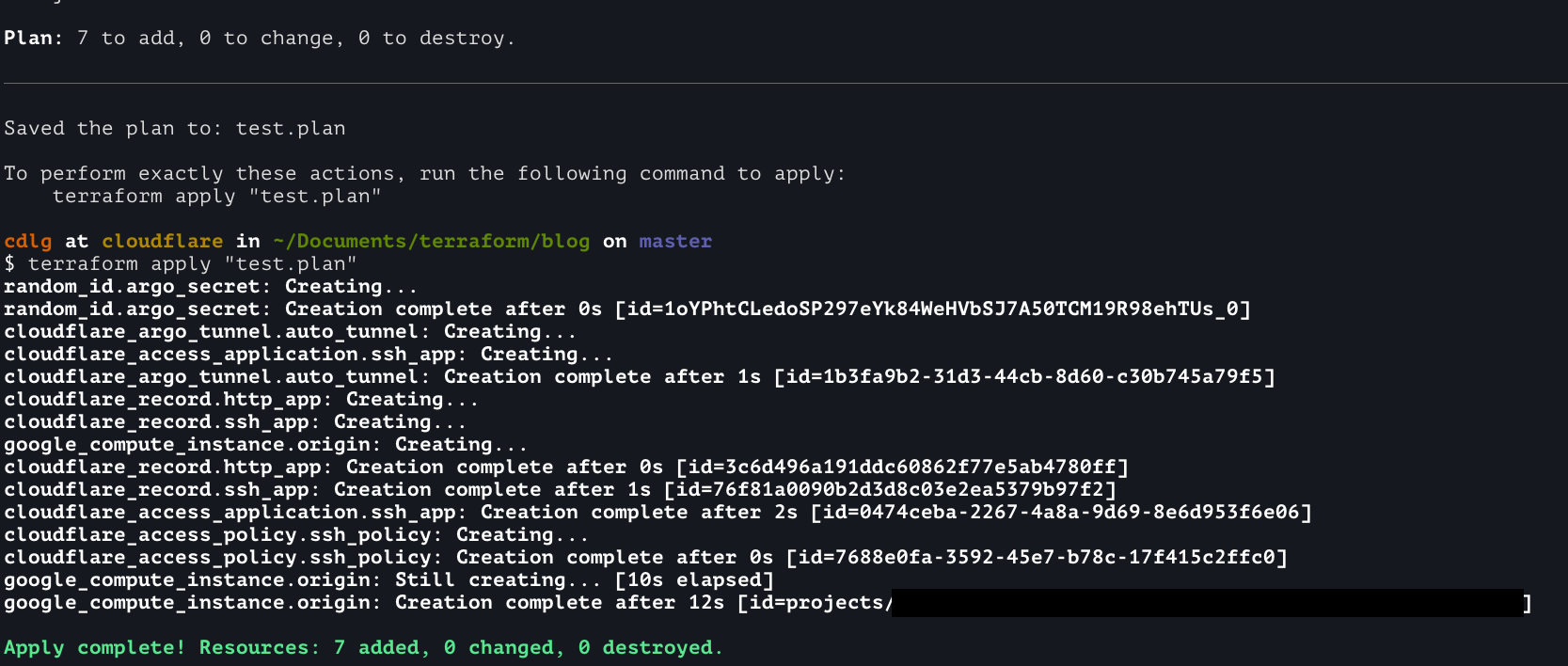
On my workstation I have cloudflared installed and updated my SSH config to proxy traffic for this SSH endpoint through cloudflared.
cdlg at cloudflare in ~
$ cloudflared --version
cloudflared version 2021.4.0 (built 2021-04-07-2111 UTC)
cdlg at cloudflare in ~
$ grep -A2 'ssh.chrisdlg.com' ~/.ssh/config
Host ssh.chrisdlg.com
IdentityFile /Users/cdlg/.ssh/google_compute_engine
ProxyCommand /usr/local/bin/cloudflared access ssh --hostname %h
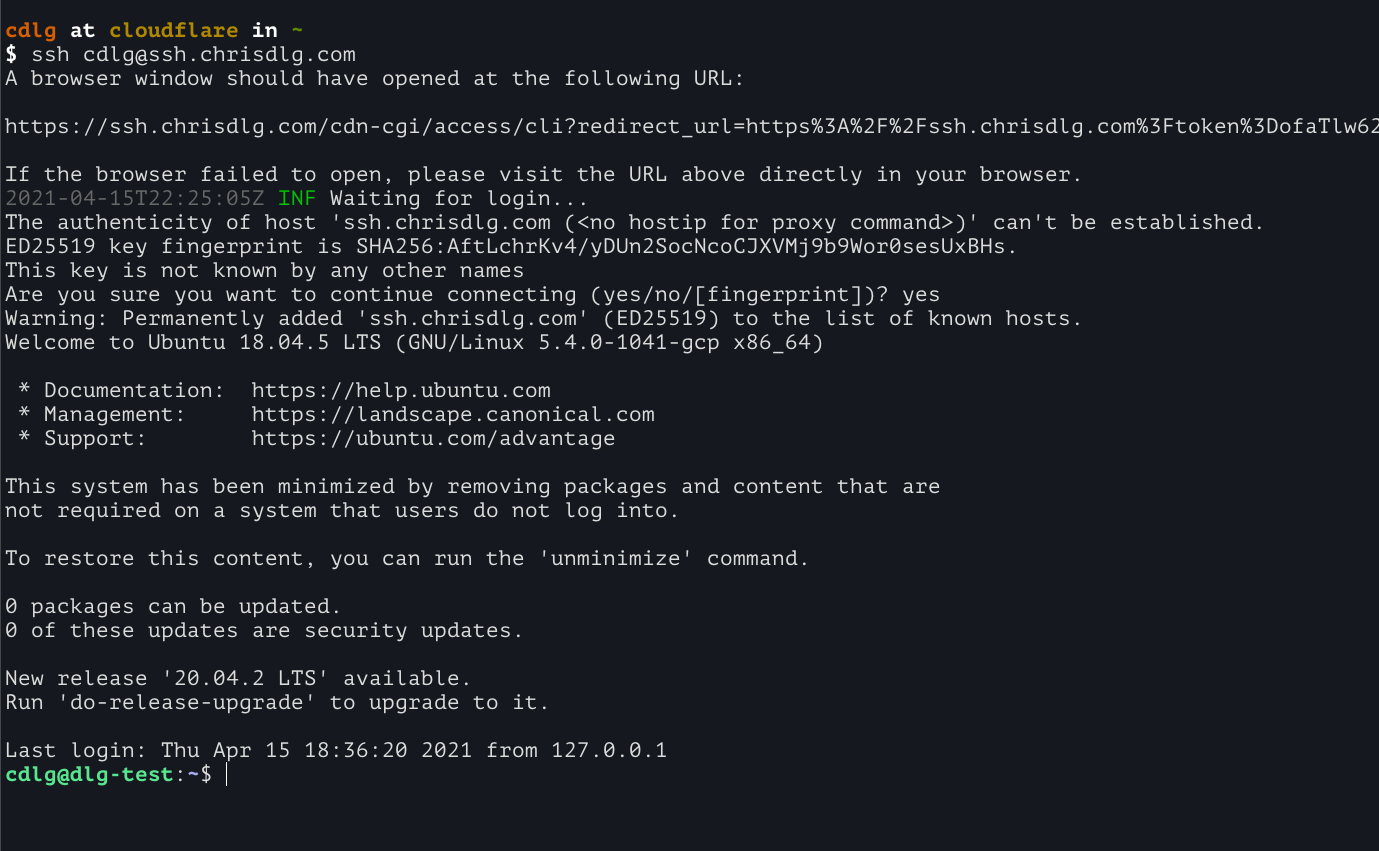
I can then SSH with my local user on the remote machine (cdlg) at the SSH hostname (ssh.chrisdlg.com). The instance of cloudflared running on my workstation will then proxy this request.

This will open a new tab in my current browser and direct me to the Cloudflare Access application recently created with Terraform. Earlier in the Access resource we set the Cloudflare user as denoted by the var.cloudflare_email variable as the criteria for the Access policy. If the correct email address is provided the user will receive an email similar to the following.
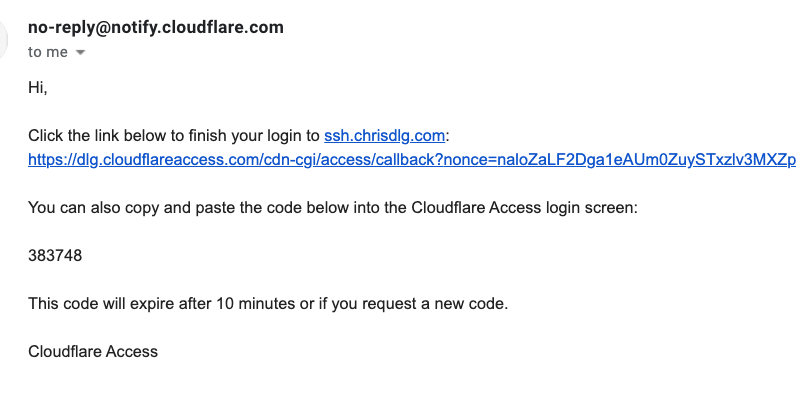
Following the link or providing the pin on the previously opened tab will complete the authentication. Hitting ‘approve’ tells Cloudflare Access that the user should be allowed through per the length of the session_duration argument in the cloudflare_access_application resource. Navigating back to the terminal we can see that we are now on the server.
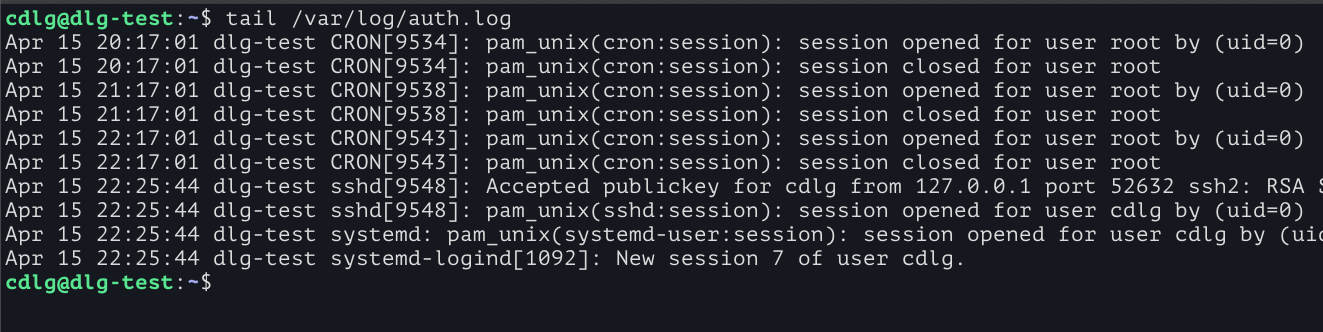
If we check the server’s authentication log we can see that connections from the tunnel are coming in via localhost (127.0.0.1). This allows us to lock down external network access on the SSH port of the server.
The full config of this deployment can be viewed here.
The roadmap for Cloudflare Tunnels is bright. Hopefully this walkthrough provided some quick context on what you can achieve with Cloudflare Tunnels and Cloudflare. Personally my dog is quite happy that I have more time to take him on walks. We’re very excited to see what you build with Cloudflare Tunnels and Cloudflare!


