Making JavaScript run fast on WebAssembly


A lot of JavaScript that runs in the browser nowadays runs quicker than it did two decades ago. And so that occurred as a result of the browser makers devoting time to rigorous speed enhancements.
To accomplish our goals today, we are beginning our efforts to enhance JavaScript performance for environments where different restrictions apply. As a result, this is achievable due of WebAssembly.
Right, this section should be self-explanatory. So, if you’re going to use JavaScript in the browser, it’s always better to deploy JS. Browsers embed JavaScript engines that are particularly efficient at executing the JavaScript that is sent to them.
The only thing to worry about is if you’re running JavaScript in a Serverless function. To learn more about just-in-time (JIT) compilation, you may be interested in reading “Just-in-Time Compilation: Bringing Just-in-Time Performance to your Applications” by Eric Roberts, Anthony Ivey, and Ben Mullikin
To certain use cases, it is especially important to keep an eye on this new wave of js optimization. In addition, this work may also be used as a template for other runtimes—such as Python, Ruby, and Lua—which also desire to run quickly in similar environments.
However, before we get into figuring out how to run up this approach, we need to make how it functions at a fundamental level.
So how does this work?
When running JavaScript, the JavaScript source code has to be executed in one of two ways: as machine code or as human-readable source code. This is accomplished by the JS engine by using various techniques like as interpreters and JIT compilers. If you would want to learn more about just-in-time (JIT) compilers, see our crash course here.
The guy with the Personified JS engine was examining the JS source code and then speaking the comparable machine code out loud
However, what if your target platform does not have a js engine? Next, you will want to deploy a js engine alongside your code.
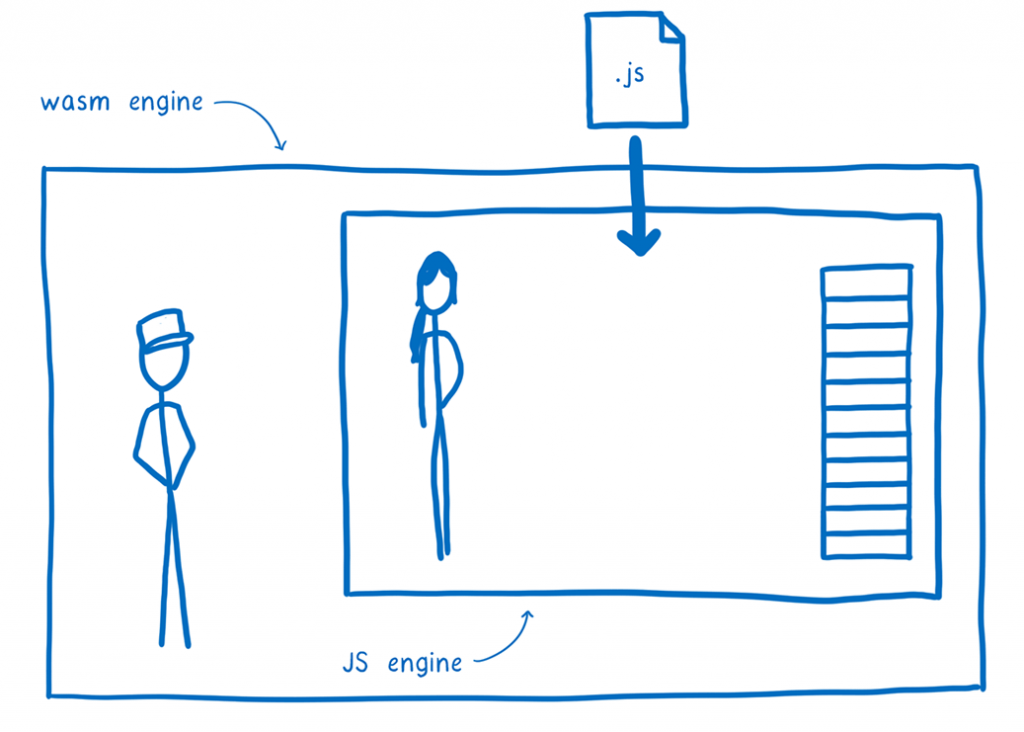
In order to achieve this, we deploy the JS engine as a WebAssembly module, which allows it to be ported across various kinds of machine architectures. Also, we can make WASI across several operating systems, which allows us to have the WASI portable utility.

In this instance, the whole js environment has been compacted into this WebAssembly instance. Once you have deployed it, all you have to do is enter the JavaScript code, and it will execute it.
A box which represents the Wasm engine wraps a box which represents the JS engine, together with a JS file that is sent from the Wasm engine to the JS engine.
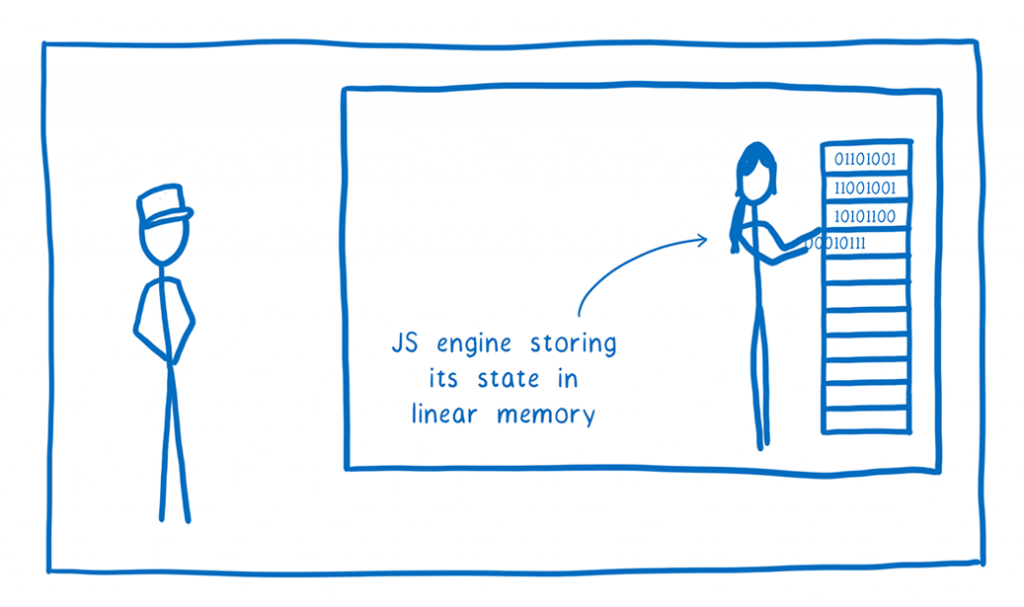
The JS engine instead works with everything: from bytecode to GCed objects that the bytecode manipulates, as well as anything else (i.e. data), which is stored into the Wasm module’s linear memory.
The JS engine, who is being modelled like a computer, inserts translated machine code bytes into the linear memory box that it is in.

For our js engine, we choose SpiderMonkey, which is currently in use in Firefox. This is one of the JavaScript VMs of industrial strength, which has seen first-hand service in the browser. It is especially important to do such frequent and expensive exercises on the software you are developing when you are running untrusted code, or code that processes untrusted input.
As a part of my optimization efforts, SpiderMonkey implements a method called exact stack scanning, which is important for the improvements that I describe below. Finally, the project’s accessible codebase is another important aspect to consider, since a group of three separate companies, namely Fastly, Mozilla, and Igalia, are all cooperating on this project.
So far, the approach I’ve outlined has shown little deviation from the status quo. A long time ago, JS developers already ran their scripts on WebAssembly (WebAssembly is similar to dynamic scripting in that regard).
The problem is that it is too sluggish. The feature that does not enable dynamic generation of machine code, but that does run the use of the Wasm in-process in the event of errors is the WebAssembly (see also Machine code). This thus means you can not utilise the JIT. You are only able to utilise the interpreter.
Since you are bound by this restriction, you may be inquiring…
On top of that, why would you do this?
When it comes to doing this, it may seem a little paradoxical, but the fact is that it is because JIT compilers are how the browsers implemented js’s rapid performance (as well as because you cannot JIT compile inside of a WebAssembly module).
in addition to “But why?”, a terrified developer cried “But why?”
In addition, we may try to make the JS programme run quickly even if this may be impossible.
So, how about looking at a handful of practical cases where this more practical approach may truly be useful?
Building and running js on iOS (and other JIT-restricted environments)
This may apply to any piece of software you have on your iOS device that is not allowed to utilise JIT compilation, including third-party places and many smart TVs and game consoles.
I just bought an iPhone, a smart TV, and a gaming controller.
In order to utilise these platforms, you must first utilise an interpreter. Also, the programmes you run on these platforms last a long time, and you will need a lot of code to get kinds done. In the context of what you have outlined, these are precisely the kinds of scenarios where traditionally you would not want to employ an interpreter, because of how much it slows down execution.
If we can make our approach as fast as possible, then these developers will be able to utilise JavaScript on JIT-less platforms without having to sacrifice performance.
Zero-downtime deployment and instant cold start with Serverless
For the aforementioned places, the problem of start-up time is an issue where serverless is not as much of a concern, but for the latter, it is all about how long it takes to start. The cold-start delay problem that you may have heard about is in effect.
The cloud-shaped network diagram shown here shows lots of edge network nodes surrounding it.
Even if you’re utilising the most most paired-down JS environment—an isolation that just starts up a bare JS engine—you’re looking at 5ms of startup latency on the good side, and up to 1s on the bad side. As well as the time it takes to start the programme, this does not even count the beginning.
When you are developing a request that will go out to the internet, there are a number of different approaches to hide the startup time. However, it is becoming more difficult to obscure this since networking time has been optimised at the network layer in proposals such as QUIC. Additionally, keeping a hidden server-side trace might be more difficult when you’re doing things like connecting numerous Serverless functions together.
Leveraging platforms that use these techniques to hide latency also often repeat instances between requests. This might lead to a security risk, as the global status may be seen while separate requests are being sent.
Unfortunately, as a result of this cold-start problem, developers do not always use recommended practises. The resulting Serverless deployment has a large lot of functions included inside it. In conclusion, this leads in another security issue—a greater explosion radius. An attacker with malicious code that gains access to a vulnerable component in a Serverless deployment may get access to everything inside that deployment.
To the left of the cartoon is the statement “Risk between requests”. It shows burglars in a room full of various documents that display the words “Oh my, payday! Let us have a look at what they left behind.” “Risk between modules” appears on the right of the caption box. It shows a tree of modules with a module at the bottom that has been destroyed, and other modules along the tree that have been damaged by shrapnel.
However, if we can hide JS start-up timings to a level low enough for certain contexts, then we would not have to do any hiding, which might result in faster start-up timings. If we can start up an instance in microseconds, everything is ok.
This expands our original statement, which said that fresh instances were available on each request, to suggest that there are no states that are left over between requests.
This relieves stress on developers, as all the instances are so lightweight. Because of this, they may disperse their code into fine-grained chunks, minimising the blast radius for any one piece of code.
On the left, a cartoon shows the concept of “request isolation.” It shows the same bugalers, but in a very sterile environment, with them claiming “Nuthin’, they did not leave anything behind.” On the right, a cartoon panel that reads “isolation between modules”. A module graph with each module and module box are shown. Next to each module is a little box that represents the module. When the module explodes, it only causes a little explosion, confined to its box.
Another advantage of this approach is that it is more secure. The fact that it is lightweight and feasible to use finer-grained isolation is not the only benefit of the Wasm security border. It is also more trustworthy.
Because JS engines, which are large codebases containing lots of low-level code that does ultra-complicated optimizations, frequently introduce bugs that enable attackers to escape the VM and gain access to the system it is running on, isolates are no longer considered to be an effective security measure. Browsers like Chrome and Firefox run several measures to isolate sites, since this is how they guarantee that each site is running in a distinct process.
On the other hand, Wasm code is simpler to audit, thus there are many new Wasm engines in development, and the majority of them are being written in Rust, a memory safe language. And verifying the memory isolation of native binaries created from a WebAssembly module may be done with the aid of the approach discussed above.
Additionally, because running the JS engine inside of a Wasm engine also provides a more secure sandbox border, it is also an additional line of protection.
Because of these practical use cases, improving JS performance on Wasm would help a lot. But how can we do that?
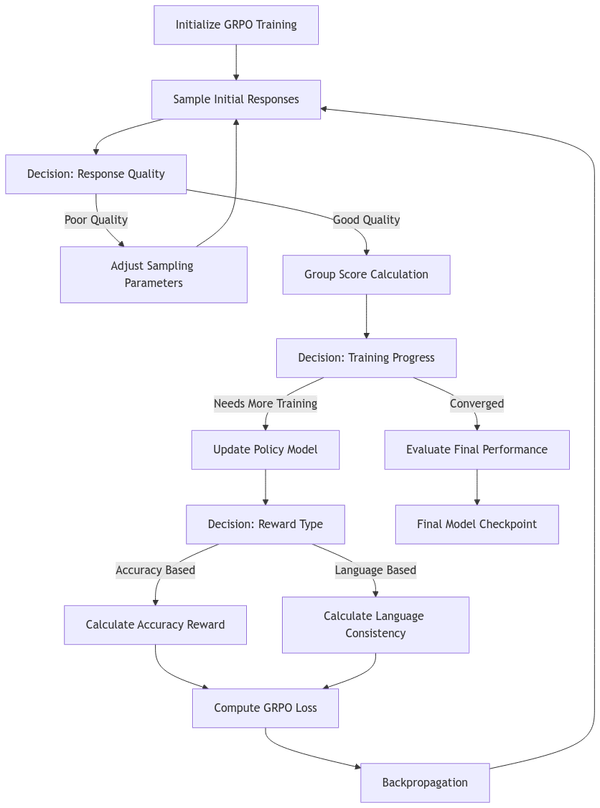
To find out the solution to that question, we must first find out where the JS engine spends its time.
The places where a js engine spends its time are:
One may break that the js engine’s work can be broadly broken down into two components: initialization and runtime.
I conceive of the JS engine as a freelance contractor. This contractor has been hired to complete a work, which is to run the JS code and come to a result.
JS files are welcomed by JS, with the JS engine shaking hands and stating, “I am excited to be able to assist you with this project.”

An initialization step
Before this contractor can really start work on the project, some preparatory work has to be completed. The initialization phase encompasses everything that has to happen just once at the beginning of the execution, i.e. initialization.
Initialization of the application
When looking at any project, the contractor must first focus on the tasks that the customer wants completed, and then determine how much of the resources he will need to complete those tasks.
This, for example, is how the contractor does business: by reading through the project briefing and other supporting papers, and transforming them into something that the project can work with, such implementing a project management system with all of the papers saved and arranged.

The JS engine was at its office doing desk work, with the JS file on the desk in front of it and asking, “Describe the additional tasks you would want to get done.”
So, in the case of the JS engine, this seems to be an easier work, in which you just have to go through the top-level of the source code and parse functions into bytecode, allocate memory for variables that are declared, and assign values where they are already specified.
Initialization of the engine
One example of a contexts where there is additional part to initialization that occurs before each application initialization is when using Serverless.
The first stage of engine initialization. To be able to execute JS code, the JS engine must be initialised first, and in addition, built-in functions must be started in the environment.
To put it another work, I see this as preparing the office environment like IKEA furniture by putting items like constructing the IKEA chairs and tables in the background.
The JS engine is creating an IKEA table for the company’s office

With part to cold starts, this may take a significant start of time, and may make another layer of complexity to Serverless application use cases.
This is the runtime phase
Once the initialization process is completed, the JS engine can get to work and start running the code.
A JS engine moves cards from the queued position on the Kanban board all the way to the done position.
All the many factors that impact the speed of the work are referred to as throughput, and this throughput is termed velocity. As an example:
characteristics of which languages are in use
The question of whether the code behaves reliably from the JS engine’s point of view
There are many different data structures, which is both interesting and perplexing.
Whether the code runs long enough to take use of the js engine’s optimising compiler is debatable.
There are two distinct phases in which the js engine spends its time.
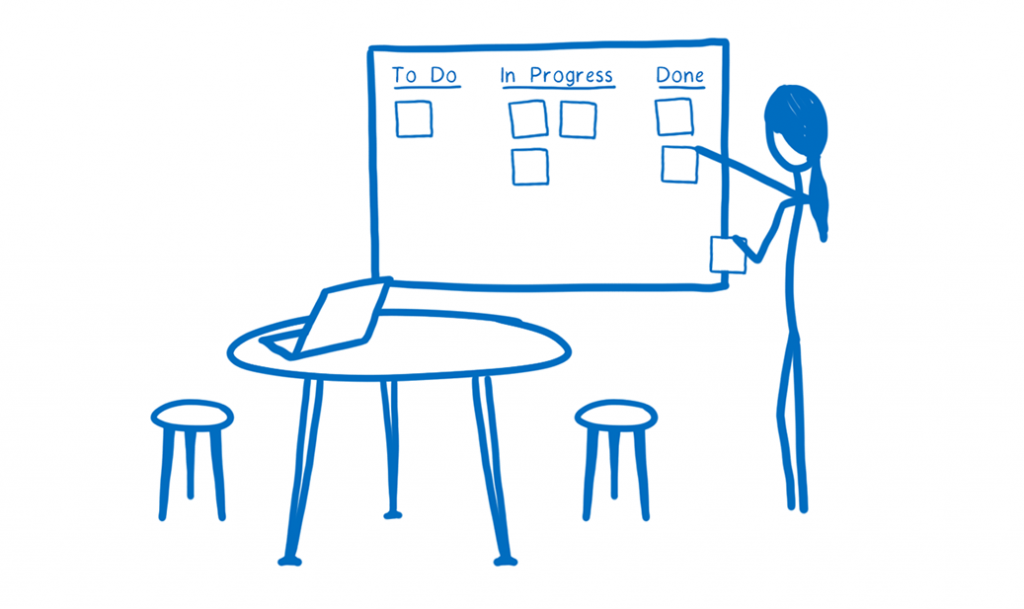
A series of the three pictures that come before this one, which shows the office building and requirements accumulating during initialization, and work being completed across the Kanban board throughout runtime.
We need to figure out how to make this work in the two phases move quicker.
Rapidly lowering the initialization time
In the beginning, we started by streamlining initialization using a tool named Wizer. Here’s how: for those who want to skip the background, here’s how we can get a quick startup time with a minimal JS app.
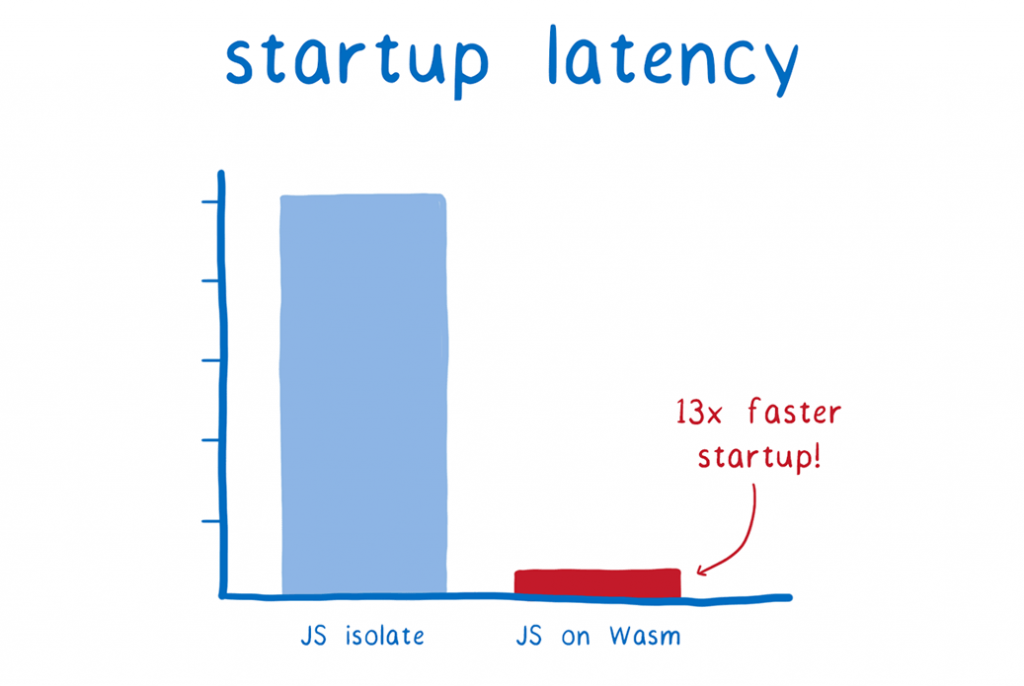
A graph demonstrating startup times on a scale of seconds. JS isolation takes 5ms, but JS on Web Assembly (Wasm) is just 0.36ms.
When using Wizer, running this little application just takes a short amount of time.
the 36 millisecond duration (or 360 microseconds). With this increase in speed, we see thirteen times more than what we’d anticipate with the JS isolation approach.
Using a tool called a snapshot, we can achieve a quick start-up for our start-up. Nick Fitzgerald explains all of this in his session at the WebAssembly Summit, in which he also discusses Wizer.
So how does this process work? Before the code is deployed, as part of a build step, we run the JS code using the JS engine all the way to the conclusion of initialization.
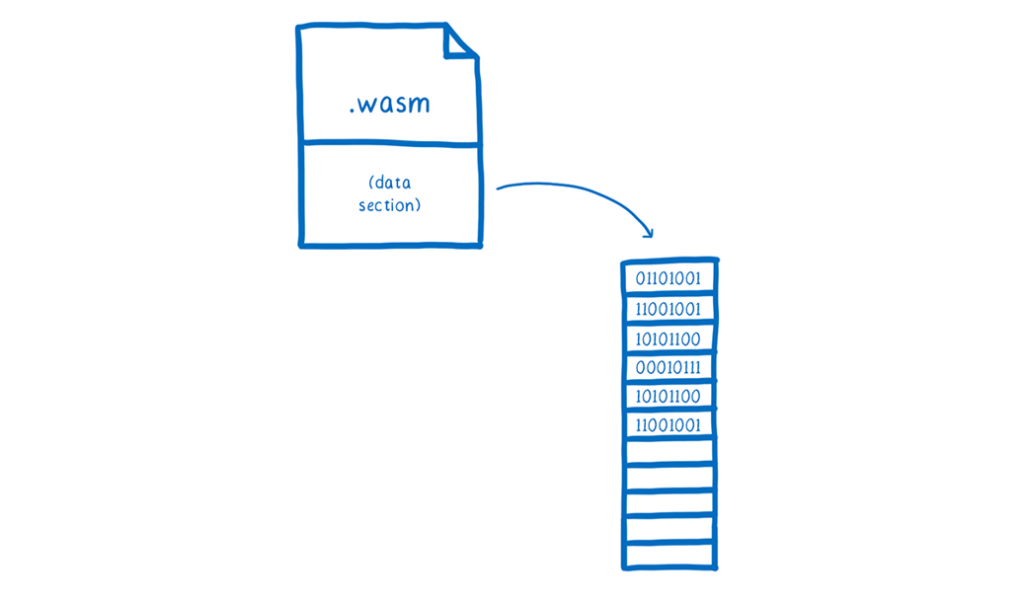
By this time, the JS engine has parsed all of the JS and compiled it into bytecode, which the JS engine module stores in the linear memory. Additionally, during this lot, the engine undertakes a great deal of memory allocation and initialization.
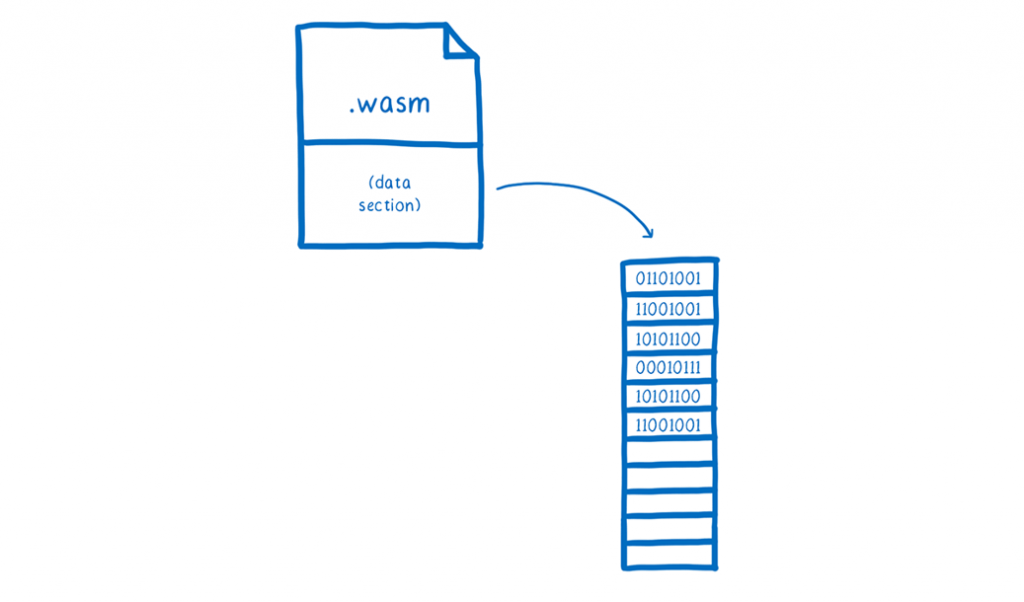
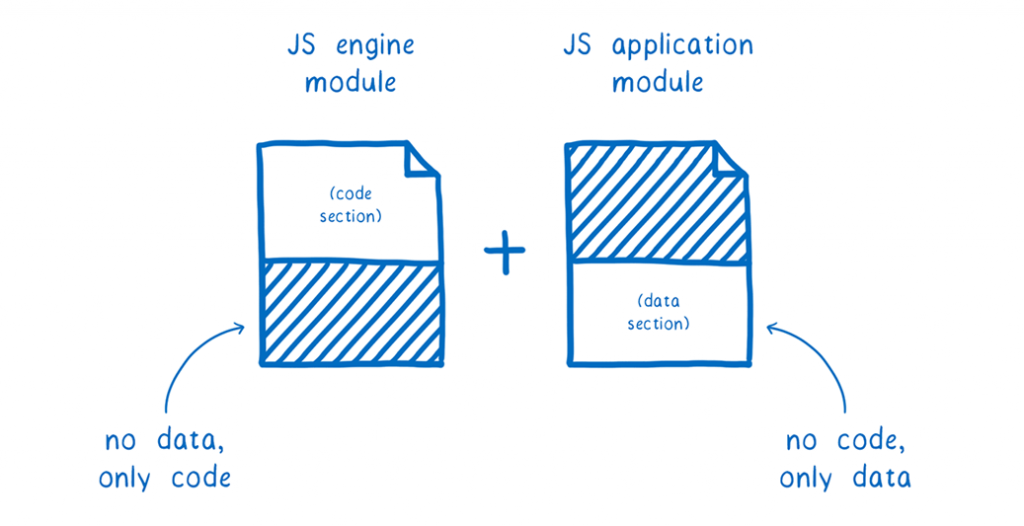
As you may have seen, this linear memory is a standalone module that has everything inside of it, including the values of all of the form elements. After they have all been filled in, we can simply attach the memory as a data section to a Wasm module.
As soon as the JS engine module is created, it gets access to all of the data in the data section. Whenever the engine requires some memory, it is able to use its own linear memory to store a duplicate of the portion (or rather, the memory page) that it requires. This means that when the JS engine is launched, it does not have to do any setup work. All of the values that have been previously initialised are ready and awaiting it.
For the time being, we always place this data part in the same module as the JavaScript engine. But in the future, once module linking is in place, we will be able to distribute the data part as a distinct module, enabling the JS engine module to be reused by many other JS apps.
This is a clean break, with nothing in the way.
There is simply the engine module code in the JS engine module. This implies that once it is compiled, the code is stored and reused over and over again in other contexts.
This means that, while it has no Wasm code, the application-specific module follows all of the specifications in the table. It is composed of solely the linear memory, which is in turn built up of the JS bytecode, and also includes the remainder of the JS engine state that was initialised. Itmakes a lot easier to transfer memory about and send it anywhere it needs to go when it is all combined in one location.
There are two wasm files placed next to each other. The JS engine module-specific code portion offers no further information, however the JS application module-specific data part has a lot of information.
Think of it as the JS engine contractor does not even have to setup an office, as they only need to remotely connect to the game servers. It receives a shipment of a travel case supplied to it. Every workstation, laptop, printer, file cabinet, and telecommunication setup in the office are all packed up and ready for the JS engine to be put to work.
The Wasm engine was now dressed in business attire and shown as a humanoid person who dropped a camera view of the JS engine’s office into the Wasm engine and then said, “Here, take this as a quick introduction to the office before you go to work.”
In addition, it is especially wonderful since the js used is not JavaScript-dependent; instead, it uses an existing property of WebAssembly. So you could use this similar strategy to other runtimes such as Python, Ruby, Lua, or other languages.
The next step is to increase throughput
With this approach, we will be able to achieve the very quick starting times. But how does throughput rate compare?
The real throughput is not as horrible as many people think it is for various use cases. But if you have a very brief running JavaScript snippet, it will not travel via the JIT, since it will remain in the interpreter the entire time. To summarise, because of it, the throughput in the browser would be the same, and the whole processing would be done before a standard JavaScript engine has done initialising.
However, if you are running js that is going to run for a longer time, the JIT will start to kick in soon after you start your code. Once the bottleneck is hit, the discrepancy in throughput becomes readily apparent.
On the subject of JIT compiling code in WebAssembly, I have said that this is not now viable. But as we investigate, we discover that we can apply some of the logic that goes along with JIT compilation to an ahead-of-time compilation approach.
Fast AOT-compiled js (without profiling)
Additionally, one optimization approach that JITs employ is inline caching. When using inline caching, the JIT generates a linked list of stubs, each of which has a list of fast machine code pathways that have all the ways a single JS bytecode instruction has been run in the past. If you would want to learn more about just-in-time (JIT) compilers, see our crash course here.
A monitor shows the “frequency feedback” from the JS engine (a man in front of a giant matrix of bytecode entries and machine code stubs) which is then used to “seed” the machine code.
The primary usage of a list is due to the dynamic types that are built into js. To add any new type that is used in a separate line of code, you need to generate a new stub and then add it to the list. This is what happens when you have run this type of structure before; all you need to do is reference the stub that was previously created for it.
The dynamic programme of inline caches (ICs) is why some believe they are employed in JITs for only a very particular set of programmes. However, it has been discovered that same rulesets may be used in an AOT environment as well.
Even before we see the JS code, we already know a lot of the IC stubs that we are going to need in order to generate it. Because JS is riddled with patterns, we need to use as many of them as possible.


An excellent illustration of this is being able to access attributes on objects. As stated before, it is quite common in JS to have unnecessary lot performed. You may make the code faster by using an IC stub. This is especially useful for objects with a certain “shape” or “hidden class” (i.e., where properties are arranged in the same manner), since when you retrieve a certain property from such objects, it will always be located at the same property.
To our knowledge, hard-coding the reference to the shape and the offset of the property has traditionally been used as the IC stub when it comes to IC stubs that are in the JIT. And to get that information, we do not have it ahead of time. But the only thing we can do is parameterize the IC stub. In order to achieve our goal, we may consider the shape and property offset as variables that are handed in to the stub.
As a result, we may build a single ‘stub’ (also known as a ‘template’) which loads values from memory, and which we can subsequently use in many other places. If the JS code always performs the same behaviour, then we can bake all of the stubs for these common patterns into the AOT generated module, independent of what the JS code does. This IC sharing is useful even in a browser scenario since it allows the JS engine to generate less machine code, which helps improve startup time and instruction cache locality.
On the other hand, for our current use cases, it is important. The only thing that means is that we can bake all of the stubs for these common patterns into the AOT generated module, independent of what the JS code does.
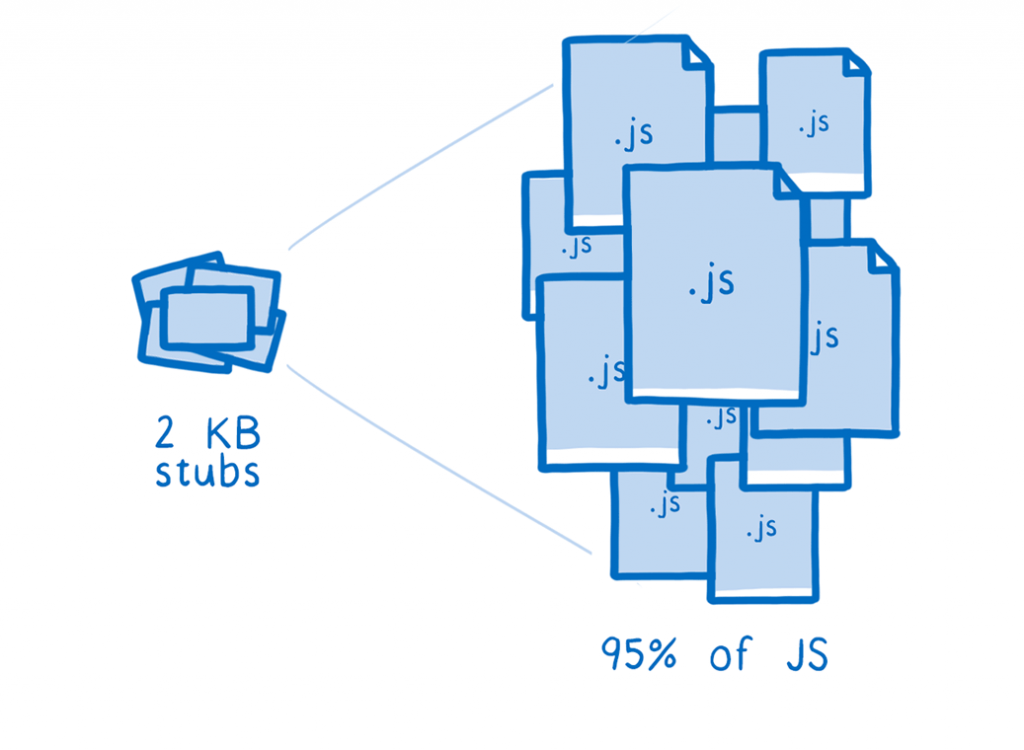
When it comes to all the js code out there, a small handful of IC stubs is enough to handle most anything. For example, with 2 KB of IC stubs, we can cover 95% of the js coverage in the Google Octane test. These first experiments have shown that this proportion holds true for normal online surfing, as well.
In the left-hand corner, a little amount of stubs and in the right-hand corner, a larger quantity of js files.
So if we use this type of optimization, we should be able to obtain throughput that is equivalent to JITs that are early in their lifecycle. Once we have finished with that work, we will add further fine-grained optimizations and fine-tune the performance, exactly like the JS engine teams of the major browsers did with their early JITs.
A next, next step: do you add profiling would be a good idea?
So that is what we can do ahead of time: without knowing what a programme does or what kinds pass through it.
The key access, however, is whether or if we could have the same type of profiling information as a JIT, which we now lack. At that point, we could then thoroughly optimise the code.
Although this is a problem, it is not nearly as bad as developers have a hard time profiling their own code. It’s difficult to provide samples of workloads that are typical of the population. To make matters worse, it is not clear if we will be able to get enough profiling data.

If we can figure out a method to use quality tools for profiling, it’s possible we could do the same thing with the JS runtime that current JITs are able to do, without incurring the warm-up time that accompanies JIT code execution.
Here’s how to get started now.
We are enthusiastic about this new approach and we are looking forward to seeing how far we can take it. We are also delighted to see more dynamically typed languages make their way to WebAssembly the same manner.
Please keep in mind that this is just a small sampling of options for starting a new task, and if you have any more queries, you may post to Zulip.
JS should be supported on platforms other than the web if they wish to.
Embedding a WebAssembly engine that supports WASI is necessary in order to run js in your own platform. Wasmtime is what we’re utilising for that.

If you are developing your application using JavaScript, you must include your JS engine. Also part of this work, we’ve introduced complete support for Mozilla’s build system for compiling SpiderMonkey to WASI. And the Mozilla project is set to add WASI builds.