
Moving Quicksilver into production

This post originally appears here
One of the great arts of software engineering is making updates and improvements to working systems without taking them offline. For some systems this can be rather easy, spin up a new web server or load balancer, redirect traffic and you’re done. For other systems, such as the core distributed data store which keeps millions of websites online, it’s a bit more of a challenge.
Quicksilver is the data store responsible for storing and distributing the billions of KV pairs used to configure the millions of sites and Internet services which use Cloudflare. In a previous post, we discussed why it was built and what it was replacing. Building it, however, was only a small part of the challenge. We needed to deploy it to production into a network which was designed to be fault tolerant and in which downtime was unacceptable.
We needed a way to deploy our new service seamlessly, and to roll back that deploy should something go wrong. Ultimately many, many, things did go wrong, and every bit of failure tolerance put into the system proved to be worth its weight in gold because none of this was visible to customers.
The Bridge
Our goal in deploying Quicksilver was to run it in parallel with our then existing KV distribution tool, Kyoto Tycoon. Once we had evaluated its performance and scalability, we would gradually phase out reads and writes to Kyoto Tycoon, until only Quicksilver was handling production traffic. To make this possible we decided to build a bridge – QSKTBridge.

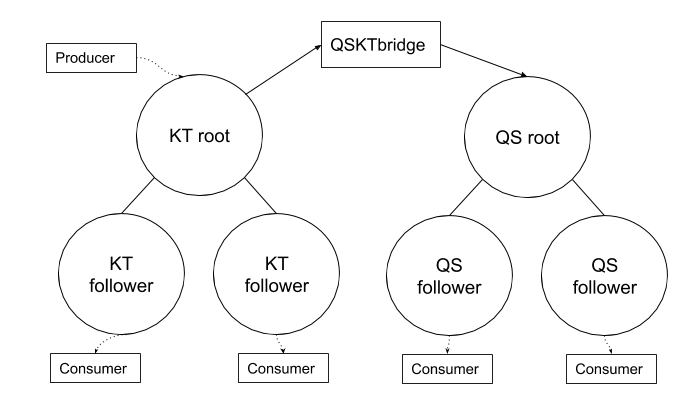
Our bridge replicated from Kyoto Tycoon, sending write and delete commands to our Quicksilver root node. This bridge service was deployed on Kubernetes within our infrastructure, consumed the Kyoto Tycoon update feed, and wrote the batched changes every 500ms.
In the event of node failure or misconfiguration it was possible for multiple bridge nodes to be live simultaneously. To prevent duplicate entries we included a timestamp with each change. When writing into Quicksilver we used the Compare And Swap command to ensure that only one batch with a given timestamp would ever be written.
First Baby Steps In To Production
Gradually we began to point reads over a loopback interface from the Kyoto Tycoon port to the Quicksilver port. Fortunately we implemented the memcached and the KT HTTP protocol to make it transparent to the many client instances that connect to Kyoto Tycoon and Quicksilver.
We began with DOG, DOG is a virtual data center which serves traffic for Cloudflare employees only. It’s called DOG because we use it for dog-fooding. Testing releases on the dog-fooding data center helps prevent serious issues from ever reaching the rest of the world. Our DOG testing went suspiciously well, so we began to move forward with more of our data centers around the world. Little did we know this rollout would take more than a year!
Replication Saturation
To make life easier for SREs provisioning a new data center, we implemented a bootstrap mechanism that pulls an entire database from a remote server. This was an easy win because our datastore library – LMDB – provides the ability to copy an entire LMDB environment to a file descriptor. Quicksilver simply wrapped this code and sent a specific version of the DB to a network socket using its file descriptor.
When bootstrapping our Quicksilver DBs to more servers, Kyoto Tycoon was still serving production traffic in parallel. As we mentioned in the first blogpost, Kyoto Tycoon has an exclusive write lock that is sensitive to I/O. We were used to the problems this can cause such as write bursts slowing down reads. This time around we found the separate bootstrap process caused issues. It filled the page cache quickly, causing I/O saturation, which impacted all production services reading from Kyoto Tycoon.
There was no easy fix to that, to bootstrap Quicksilver DBs in a datacenter we’d have to wait until it was moved offline for maintenance, which pushed the schedule beyond our initial estimates. Once we had a data center deployment we could finally see metrics of Quicksilver running in the wild. It was important to validate that the performance was healthy before moving on to the next data center. This required coordination with the engineering teams that consume from Quicksilver.
The FL (front line) test candidate
Many requests reaching Cloudflare’s edge are forwarded to a component called FL, which acts as the “brain”. It uses multiple configuration values to decide what to do with the request. It might apply the WAF, pass the request to Workers and so on. FL requires a lot of QS access, so it was the perfect candidate to help validate Quicksilver performance in a real environment.
Here are some screenshots showing FL metrics. The vertical red line marks the switchover point, on the left of the line is Kyoto Tycoon, on the right is Quicksilver. The drop immediately before the line is due to the upgrade procedure itself. We saw an immediate and significant improvement in error rates and response time by migrating to Quicksilver.
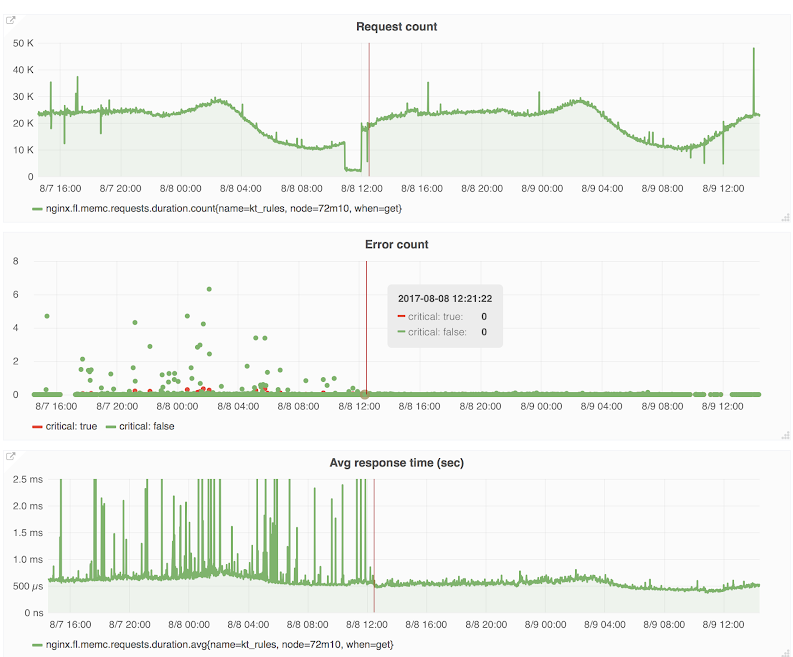
The middle graph shows the error count. Green dot errors are non-critical errors: the first request to Kyoto Tycoon/Quicksilver failed so FL will try again. The red dot errors are the critical ones, they mean the second request also failed. In that case FL will return an error code to an end user. Both counts decreased substantially.
The bottom graph shows the read latency average from Kyoto Tycoon/Quicksilver. The average drops a lot and is usually around 500 microseconds and no longer reaches 1ms which it used to do quite often with Kyoto Tycoon.
Some readers may notice a few things. First of all, it was said earlier that the consumers were reading through the loopback interface. How come we experience errors there? How come we need 500us to read from Quicksilver?
At that time Cloudflare had some old SSDs and these could sometimes take hundreds of milliseconds to respond and this was affecting the response time from Quicksilver hence triggering read timeout from FL.
That was also obviously increasing the average response time above.
From there, some readers would ask why using averages and not percentiles? This screenshot dates back to 2017 and at that time the tool used for gathering FL metrics did not offer percentiles, only min, max and average.
Also, back then, all consumers were reading through TCP over loopback. Later on we switched to Unix socket.
Finally, we enabled memcached and KT HTTP malformed request detection. It appears that some consumers were sending us bogus requests and not monitoring the value returned properly, so they could not detect any error. We are now alerting on all bogus requests as this should never happen.
Spotting the wood for the trees
Removing Kyoto Tycoon on the edge took around a year. We’d done a lot of work already but rolling Quicksilver out to production services meant the project was just getting started. Thanks to the new metrics we put in place, we learned a lot about how things actually happen in the wild. And this let us come up with some ideas for improvement.
Our biggest surprise was that most of our replication delays were caused by saturated I/O and not network issues. This is something we could not easily see with Kyoto Tycoon. A server experiencing I/O contention could take seconds to write a batch to disk. It slowly became out of sync and then failed to propagate updates fast enough to its own clients, causing them to fall out of sync. The workaround was quite simple, if the latest received transaction log is over 30 seconds old, Quicksilver would disconnect and try the next server in the list of sources.
This was again an issue caused by aging SSDs. When a disk reaches that state it is very likely to be queued for a hardware replacement.
We quickly had to address another weakness in our codebase. A Quicksilver instance which was not currently replicating from a remote server would stop its own replication server, forcing clients to disconnect and reconnect somewhere else. The problem is this behavior has a cascading effect, if an intermediate server disconnects from its server to move somewhere else, it will disconnect all its clients, etc. The problem was compounded by an exponential backoff approach. In some parts of the world our replication topology has six layers, triggering the backoff many times caused significant and unnecessary replication lag. Ultimately the feature was fully removed.
Reads, writes, and sad SSDs
We discovered that we had been underestimating the frequency of I/O errors and their effect on performance. LMDB maps the database file into memory and when the kernel experiences an I/O error while accessing the SSD, it will terminate Quicksilver with a SIGBUS. We could see these in kernel logs. I/O errors are a sign of unhealthy disks and cause us to see spikes in Quicksilver’s read and write latency metrics. They can also cause spikes in the system load average, which affects all running services. When I/O errors occur, a check usually finds such disks are close to their maximum allowed write cycles, and further writes will cause a permanent failure.
Something we didn’t anticipate was LMDB’s interaction with our filesystem, causing high write amplification that increased I/O load and accelerated the wear and tear of our SSDs. For example, when Quicksilver wrote 1 megabyte, 30 megabytes were flushed to disk. This amplification is due to LMDB copy-on-write, writing a 2 byte key-value (KV) pair ends up copying the whole page. That was the price to pay for crashproof storage. We’ve seen amplification factors between 1.5X and 80X. All of this happens before any internal amplification that might happen in an SSD.
We also spotted that some producers kept writing the same KV pair over and over. Although we saw low rates of 50 writes per second, considering the amplification problem above, repetition increased pressure on SSDs. To fix this we just drop identical KV writes on the root node.
Where does a server replicate from?
Each small data center replicates from multiple bigger sites and these replicate from our two core data centers. To decide which data centers to use, we talk to the Network team, get an answer and hardcode the topology in Salt, the same place we configure all our infrastructure.
Each replication node is identified using IP addresses in our Salt configuration. This is quite a rigid way of doing things, wouldn’t DNS be easier? The interesting thing is that Quicksilver is a source of DNS for customers and Cloudflare infrastructure. We do not want Quicksilver to become dependent on itself, that could lead to problems.
While this somewhat rigid way of configuring topology works fine, as Cloudflare continues to scale there is room for improvement. Configuring Salt can be tricky and changes need to be thoroughly tested to avoid breaking things. It would be nicer for us to have a way to build the topology more dynamically, allowing us to more easily respond to any changes in network details and provision new data centers. That is something we are working on.
Removing Kyoto Tycoon from the Edge
Migrating services away from Kyoto Tycoon requires identifying them. There were some obvious candidates like FL and DNS which play a big part in day-to-day Cloudflare activity and do a lot of reads. But the tricky part to completely removing Kyoto Tycoon is in finding all the services that use it.
We informed engineering teams of our migration work but that was not enough. Some consumers get less attention because they were done during a research activity, or they run as part of a team’s side project. We added some logging code into Kyoto Tycoon so we could see who exactly was connecting and reached out directly to them. That’s a good way to catch the consumers that are permanently connected or connect often. However, some consumers only connect rarely and briefly, for example at startup time to load some configuration. So this takes time.
We also spotted some special cases that used exotic setups like using stunnel to read from the memcached interface remotely. That might have been a “quick-win” back in the day but its technical debt that has to be paid off; we now strictly enforce the methods that consumers use to access Quicksilver.
The migration activity was steady and methodical and it took a few months. We deployed Quicksilver per group of data centers and instance by instance, removing Kyoto Tycoon only when we deemed it ready. We needed to support two sets of configuration and alerting in parallel. That’s not ideal but it gave us confidence and ensured that customers were not disrupted. The only thing they might have noticed is the performance improvement!
Quicksilver, Core side, welcome to the mouth of technical debt madness
Once the edge migration was complete, it was time to take care of the core data centers. We just dealt with 200+ data centers so doing two should be easy right? Well no, the edge side of Quicksilver uses the reading interface, the core side is the writing interface so it is a totally different kind of job. Removing Kyoto Tycoon from the core was harder than the edge.
Many Kyoto Tycoon components were all running on a single physical server – the Kyoto Tycoon root node. This single point of failure had become a growing risk over the years. It had been responsible for incidents, for example it once completely disappeared due to faulty hardware. In that emergency we had to start all services on a backup server. The move to Quicksilver was a great opportunity to remove the Kyoto Tycoon root node server. This was a daunting task and almost all the engineering teams across the company got involved.
Note: Cloudflare’s migration from Marathon to Kubernetes was happening in parallel to this task so each time we refer to Kubernetes it is likely that the job was started on Marathon before being migrated later on.
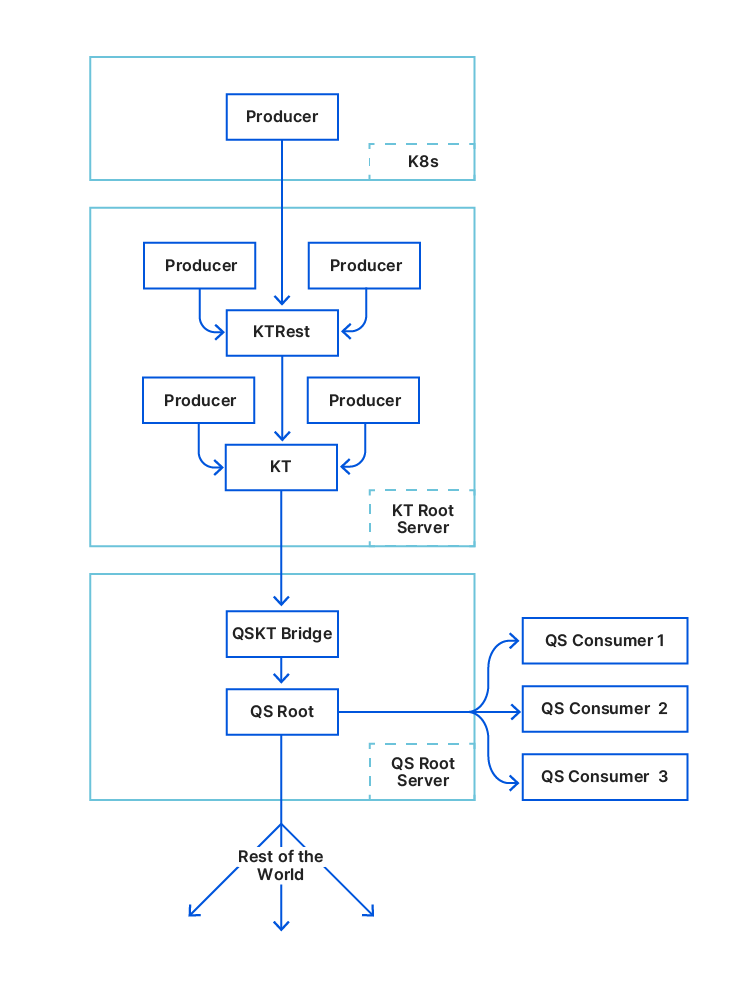
From KTrest to QSrest
KTrest is a stateless service providing a REST interface for writing and deleting KV pairs from Kyoto Tycoon. Its only purpose is to enforce access control (ACL) so engineering teams do not experience accidental keyspace overlap. Of course, sometimes keyspaces are shared on purpose but it is not the norm.
The Quicksilver team took ownership of KTrest and migrated it from the root server to Kubernetes. We asked all teams to move their KTrest producers to Kubernetes as well. This went smoothly and did not require code changes in the services.
Our goal was to move people to Quicksilver, so we built QSrest, a KTrest compatible service for Quicksilver. Remember the problem about disk load? The QSKTBridge was in charge of batching: aggregating 500ms of updates before flushing to Quicksilver, to help our SSDs cope with our sync frequency. If we moved people to QSrest, it needed to support batching too. So it does. We used QSrest as an opportunity to implement write quotas. Once a quota is reached, all further writes from the same producer would be slowed down until the quota goes back to normal.
We found that not all teams actually used KTrest. Many teams were still writing directly to Kyoto Tycoon. One reason for this is that they were sending large range read requests in order to read thousands of keys in one shot – a feature that KTrest did not provide. People might ask why we would allow reads on a write interface. This is an unfortunate historical artefact and we wanted to put things right. Large range requests would hurt Quicksilver (we learned this from our experience with the bootstrap mechanism) so we added a cluster of servers which would serve these range requests: the Quicksilver consumer nodes. We asked the teams to switch their writes to KTrest and their reads to Quicksilver consumers.
Once the migration of the producers out of the root node was complete, we asked teams to start switching from KTrest to QSrest. Once the move was started, moving back would be really hard: our Kyoto Tycoon and Quicksilver DB were now inconsistent. We had to move over 50 producers, owned by teams in different time zones. So we did it one after another while carefully babysitting our servers to spot any early warning which could end up in an incident.
Once we were all done, we then started to look at Kyoto Tycoon transaction logs: is there something still writing to it? We found an obsolete heartbeat mechanism which was shut down.
Finally, Kyoto Tycoon root processes were turned off to never be turned on again.
Removing Kyoto Tycoon from all over Cloudflare ended up taking four years.
No hardware single point of failure
We have made great progress, Kyoto Tycoon is no longer among us, we smoothly moved all Cloudflare services to Quicksilver, our new KV store. And things now look more like this.
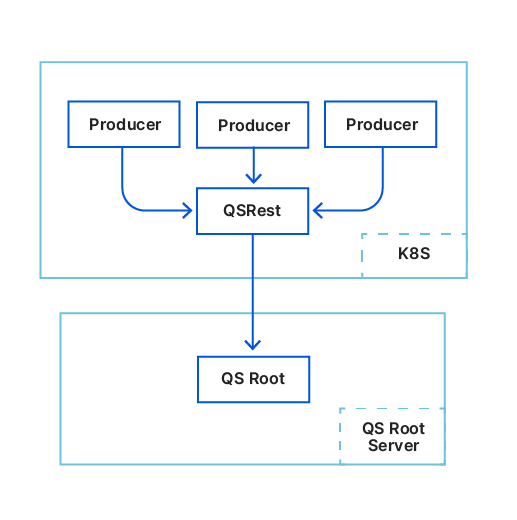
The job is still far from done though. The Quicksilver root server was still a single point of failure, so we decided to build Quicksilver Raft – a Raft-enabled root cluster using the etcd Raft package. It was harder than I originally thought. Adding Raft into Quicksilver required proper synchronization between the Raft snapshot and the current Quicksilver DB. Sometimes there are situations where Quicksilver needs to fall back to asynchronous replication to catch up before doing proper Raft synchronous writes. Getting all of this to work required deep changes in our code base, which also proved to be hard to build proper unit and integration tests. But removing single points of failure is worth it.
Introducing QSQSBridge
We like to test our components in an environment very close to production before releasing it. How do we test the core side/writer interface of Quicksilver then? Well the days of Kyoto Tycoon, we used to have a second Quicksilver root node feeding from Kyoto Tycoon through the KTQSbridge. In turn, some very small data centers were being fed from that root node. When Kyoto Tycoon was removed we lost that capability, limiting our testing. So we built QSQSbridge, which replicates from a Quicksilver instance and writes to a Quicksilver root node.
Removing the Quicksilver legacy top-main
With Quicksilver Raft and QSQSbridge in place, we tested three small data centers replicating from the test Raft cluster over the course of weeks. We then wanted to promote the high availability (HA) cluster and make the whole world replicate from it. In the same way we did for Kyoto Tycoon removal, we wanted to be able to roll back at any time if things go wrong.
Ultimately we reworked the QSQSbridge so that it builds compatible transaction logs with the feeding root node. That way, we started to move groups of data centers underneath the Raft cluster and we could, at any time, move them back to the legacy lop-main.
We started with this:
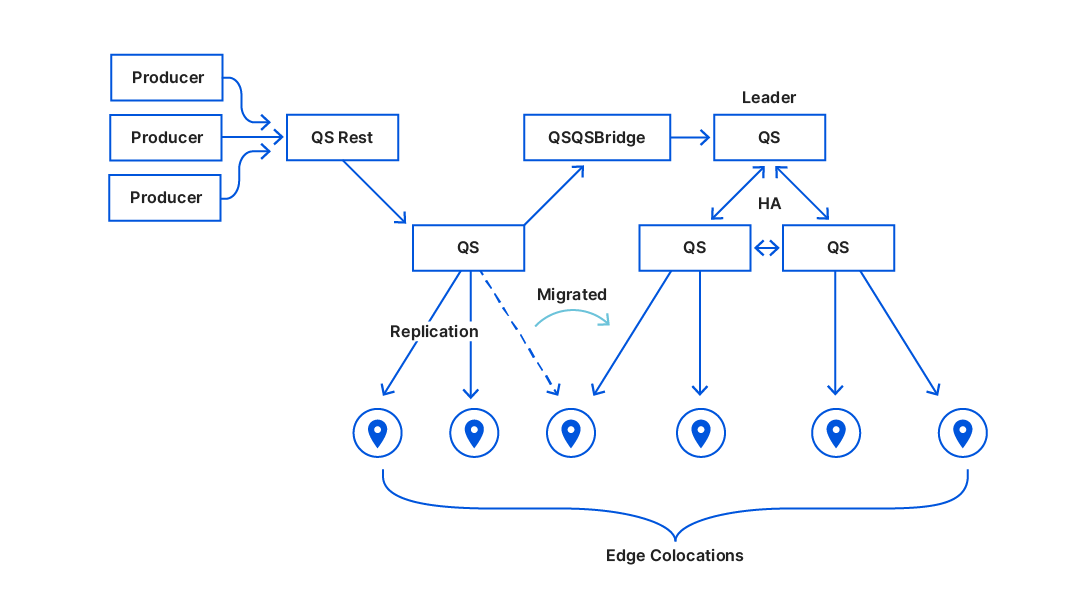
We moved our 10 QSrest instances one after another from the legacy root node to write against the HA cluster. We did this slowly without any significant issue and we were finally able to turn off the legacy top-main.This is what we ended up with:
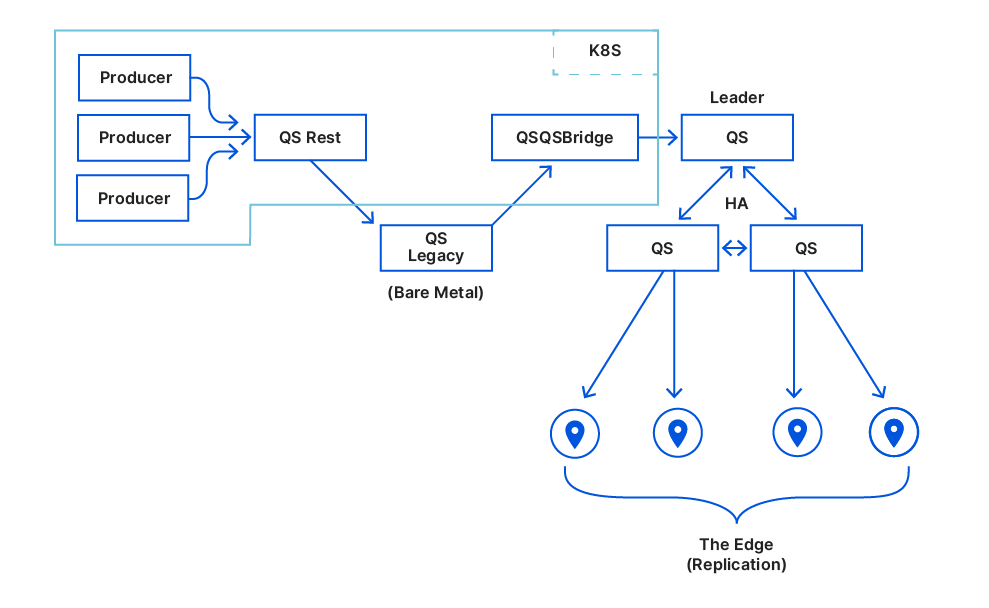
And that was it, Quicksilver was running in the wild without a hardware single point of failure.
First signs of obsolescence
The Quicksilver bootstrap mechanism we built to make SRE life better worked by pulling a full copy of a database but it had pains. When bootstrapping begins, a long lived read transaction is opened on the server, it must keep the DB version requested intact while also applying new log entries. This causes two problems. First, if the read is interrupted by something like a network glitch the read transaction is closed and the version of the DB is not available anymore. The entire process has to start from scratch. Secondly, it causes fragmentation in the source DB, which requires somebody to go and compact it.
For the first six months, the databases were fairly small and everything worked fine. However, as our databases continued to grow, these two problems came to fruition. Longer transfers are at risk of network glitches and the problem compounds, especially for more remote data centers. Longer transfers mean more fragmentation and more time compacting it. Bootstrapping was becoming a pain.
One day an SRE reported that manually bootstrapping instances one after another was much faster than bootstrapping all together in parallel. We investigated and saw that when all Quicksilver instances were bootstrapping at the same time the kernel and SSD were overwhelmed swapping pages. There was page cache contention caused by the ratio of the combined size of the DBs vs. available physical memory.
The workaround was to serialize bootstrapping across instances. We did this by implementing a lock between Quicksilver processes, a client grabs the lock to bootstrap and gives it back once done, ready for the next client. The lock moves around in round robin fashion forever.
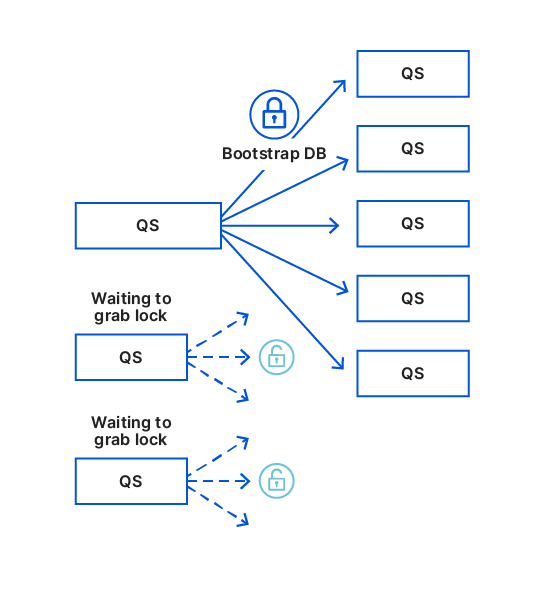
Unfortunately, we hit another page cache thrashing issue. We know that LMDB mostly does random I/O but we turned on readahead to load as much DB as possible into memory. But again as our DBs grew, the readahead started evicting useful pages. So we improved the performance by… disabling it.
Our biggest issue by far though is more fundamental: disk space and wear and tear! Each and every server in Cloudflare stores the same data. So a piece of data one megabyte in size consumes at least 10 gigabytes globally. To accommodate continued growth you can add more disks, replace dying disks, and use bigger disks. That’s not a very sustainable solution. It became clear that the Quicksilver design we came up with five years ago was becoming obsolete and needed a rethink. We approach that problem both in the short term and long term.
The long and short of it
In the long term we are now working on a sharded version of Quicksilver. This will avoid storing all data on all machines but guarantee the entire dataset is in each data center.
In the shorter term we have addressed our storage size problems with a few approaches.
Many engineering teams did not even know how many bytes of Quicksilver they used. Some might have had an impression that storage is free. We built a service named “QSusage” which uses the QSrest ACL to match KV with their owner and computes the total disk space used per producer, including Quicksilver metadata. This service allows teams to better understand their usage and pace of growth.
We also built a service name “QSanalytics” to help answer the question “How do I know which of my KV pairs are never used?”. It gathers all keys being accessed all over Cloudflare, aggregates these and pushes these into a ClickHouse cluster and we store these information over a 30 days rolling window. There’s no sampling here, we keep track of all read access. We can easily report back to engineering teams responsible for unused keys, they can consider if these can be deleted or must be kept.
Some of our issues are caused by the storage engine LMDB. So we started to look around and got quickly interested in RocksDB. It provides built in compression, online defragmentation and other features like prefix deduplication.
We ran some tests using representative Quicksilver data and they seemed to show that RocksDB could store the same data in 40% of the space compared to LMDB. Read latency was a little bit higher in some cases but nothing too serious. CPU usage was also higher, using around 150% of CPU time compared to LMDBs 70%. Write amplification appeared to be much lower, giving some relief to our SSD and the opportunity to ingest more data.
We decided to switch to RocksDB to help sustain our growing product and customer bases. In a follow-up blog we’ll do a deeper dive into performance comparisons and explain how we managed to switch the entire business without impacting customers at all.
Conclusion
Migrating from Kyoto Tycoon to Quicksilver was no mean feat. It required company-wide collaboration, time and patience to smoothly roll out a new system without impacting customers. We’ve removed single points of failure and improved the performance of database access, which helps to deliver a better experience.
In the process of moving to Quicksilver we learned a lot. Issues that were unknown at design time were surfaced by running software and services at scale. Furthermore, as the customer and product base grows and their requirements change, we’ve got new insight into what our KV store needs to do in the future. Quicksilver gives us a solid technical platform to do this.