A Unified Transformer-Based Approach to Multi-View, Spatiotemporal, and Linguistic Representations for Autonomous Driving
Modern autonomous driving perception faces extreme data volume and semantic depth complexity. Such systems must integrate multi-camera image streams into a stable three-dimensional world model, align observations over time to handle dynamic scenarios.
Contemporary autonomous driving perception must contend with an extraordinary degree of complexity in both data volume and semantic depth. Such systems must integrate multi-camera image streams into a stable three-dimensional world model, align observations over time to handle dynamic scenarios, and produce topologically meaningful abstractions that inform navigation and decision-making. They must effectively combine methods from computer vision, spatiotemporal modeling, and even concepts akin to natural language processing to represent intricate lane structures and other map elements.
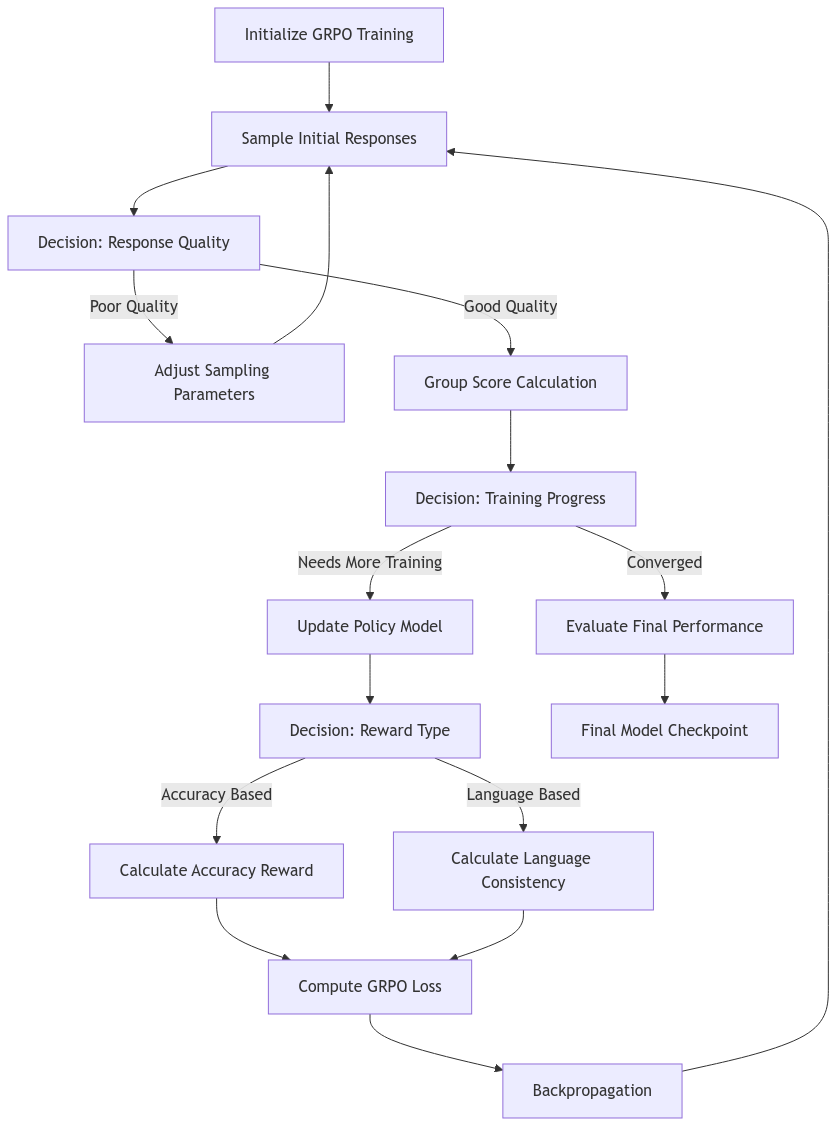
This article details a cutting-edge pipeline that distills raw camera inputs into a coherent volumetric representation and then further refines these data into structured, “linguistic” lane graphs. Drawing from transformer-based attention, temporal feature alignment, continuous volumetric queries, and autoregressive decoding, we explore how complex driving environments can be understood, navigated, and ultimately controlled with unprecedented fidelity. Mermaid.js flowcharts are interspersed to illustrate critical steps in the pipeline.
In early autonomous driving research, reliance on pairwise stereo vision, handcrafted features, and geometric heuristics imposed severe limitations. Modern perception stacks have since evolved to embrace end-to-end learned representations, attention-based architectures, and continuous volumetric modeling. Along the way, they have grown capable of encoding scene elements not only as static constructs but as topological entities akin to sentences and words in a linguistic system. With this paradigm shift, we can better handle the complexity of urban intersections, multi-lane highways, and the subtleties of object interactions.
Camera Input and Rectification
The pipeline begins with multiple cameras placed around the vehicle. Each camera feed must be corrected for lens distortions and projected into a known geometric reference frame.
After rectification, all images are standardized, easing the burden on subsequent modules by presenting a consistent geometric starting point.
Multi-Scale Feature Extraction
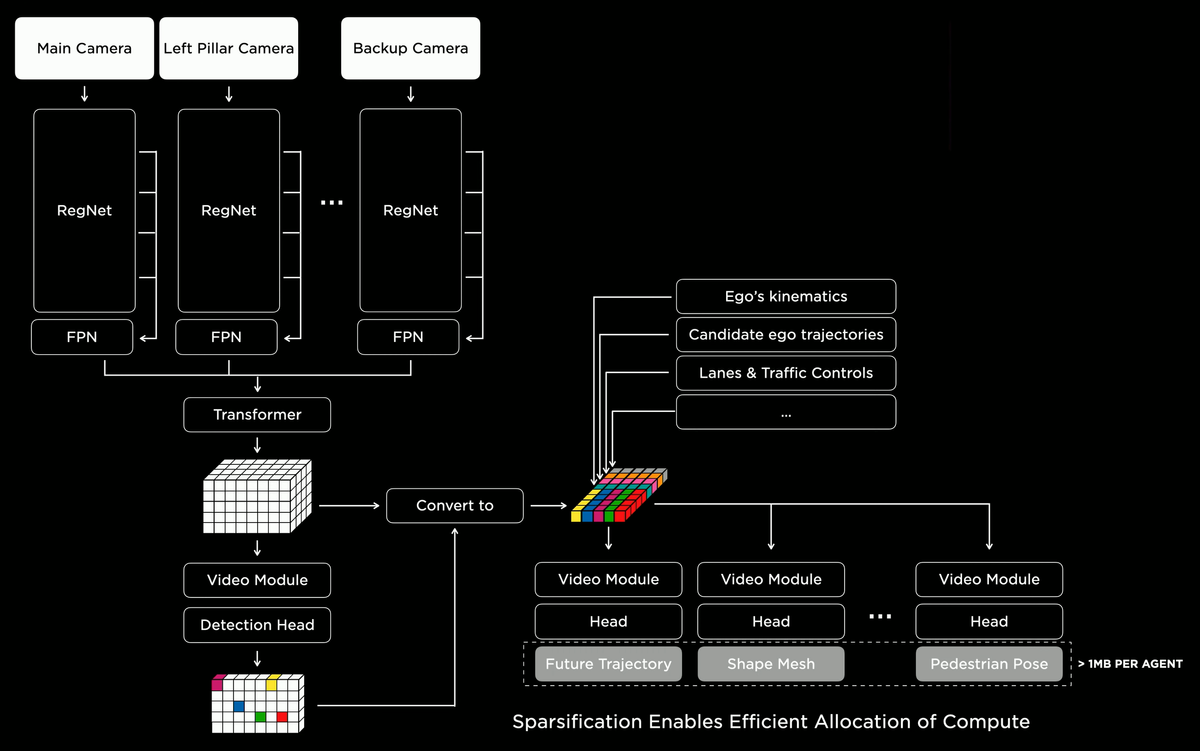
Once images are rectified, they flow through robust backbone networks (e.g., RegNet) that extract hierarchical features. The subsequent BiFPN (Bi-Directional Feature Pyramid Network) merges these features across scales to preserve both fine detail and holistic scene context.
At this stage, each camera view is represented as a set of powerful, multi-scale feature maps, poised for integration across viewpoints.
Spatial Fusion via Transformer-Based Attention
Integrating multiple camera views into a unified spatial representation is accomplished by a transformer-inspired attention mechanism. Instead of painstakingly computing explicit geometry for fusion, the network learns to attend to complementary viewpoints, using query-key-value attention.
This attention module effectively learns a mapping that yields a consistent and coherent spatial representation from multiple viewpoints, handling occlusions and reinforcing structural cues by learning when and how to combine features from different cameras.
Temporal Alignment and Spatiotemporal Fusion
Scenes evolve over time. To handle dynamics, the pipeline stores historical feature tensors. These past representations are temporally aligned—warped into the current frame’s coordinate system—using ego-motion and object-motion cues. The fused result is a spatiotemporal representation that leverages past knowledge to stabilize perception and enhance predictive capabilities.
Now, the representation is not just a static snapshot but a composite encoding of current and historical states. This temporal context is critical for understanding object trajectories, predicting future states, and smoothing out momentary ambiguities.
Volumetric Reconstruction and Continuous Queries
The combined spatiotemporal features are still compressed. They are expanded into a volumetric representation (a 3D grid or tensor) via 3D deconvolutions. This volumetric form encodes occupancy, motion flows, and semantic classes. Additionally, continuous query heads (small MLPs) can query any 3D coordinate within this learned latent space.
The capability to perform continuous queries frees the system from fixed voxel resolutions, enabling fine-grained checks of arbitrary points in space for occupancy probabilities or semantic insights.
Extracting Road Surfaces and Navigable Geometry
Volumetric outputs, while useful, are often too dense. One of the specialized “heads” or decoders in the pipeline focuses on extracting drivable surfaces and road geometry. This step can be seen as converting raw volumetric data into explicit surface representations—modeling not only where the road lies but also how it curves, where lane boundaries exist, and where curbs or sidewalks reside.
This layered understanding helps the planning subsystem differentiate between navigable road areas and obstacles or non-drivable zones.
The “Language of Lanes”
To navigate complex infrastructures, lane structures and their connectivity patterns must be recognized. Instead of merely detecting lane paint lines in a pixelwise manner, the system encodes lanes as sequences of points and topological relations. Drawing inspiration from natural language processing, it uses autoregressive decoding with transformer modules to represent lane layouts as a “language” of lane segments and branching structures.
This conceptual leap from raw vision cues to a linguistic-like lane representation enables the system to handle complex intersections, merges, and forks in a manner that allows easier integration into navigation and planning processes.
Integrating Trajectories, Agents, and Traffic Controls
The pipeline’s versatility is evident when it produces multiple outputs through specialized heads. Beyond lane structures, it can generate predictions of the ego-vehicle’s future motion, candidate trajectories conditioned on observed scene dynamics, and identify traffic controls like stop signs or signals. Additional heads focus on surrounding agents, providing occupancy predictions, shapes, and poses that inform safe and efficient driving maneuvers.
By modularizing these outputs, the pipeline can be extended or specialized to various driving conditions and objectives, all while maintaining a coherent and integrated world model.
Computational Efficiency and Sparsification
While the approach is powerful, it must remain computationally feasible for real-time operation. Strategies like sparsification and hierarchical processing ensure that the pipeline allocates computational resources to regions or tasks that matter most—focusing on nearby objects, critical intersection areas, and dynamically evolving lanes rather than uniformly processing every voxel to the same level of detail.
Such dynamic resource management is vital for deployment in real-world vehicles, where latency and energy consumption must be carefully controlled.
Outlook
We have traced the evolution from raw multi-camera inputs, through hierarchical feature extraction, transformer-based multi-view fusion, and temporal integration, culminating in a volumetric world representation. On top of these steps, the system constructs a “language” of lanes and road structures, enabling interpretations that resonate with how humans think about navigation: not as a set of disconnected pixels, but as structured pathways and maneuvers.
This paradigm sets the stage for future enhancements. We may soon witness richer, more intricate “linguistic” abstractions, broader integration of other sensor modalities (e.g., LiDAR, radar), and even tighter coupling between perception and planning. The entire pipeline provides a generative framework from which autonomous systems can “understand” their environment more holistically, modeling it in ways that foster safe, reliable, and contextually aware navigation.
References and Suggested Reading:
- [1] Carion, N. et al. “End-to-End Object Detection with Transformers.” ECCV, 2020.
- [2] Dosovitskiy, A. et al. “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.” ICLR, 2021.
- [3] Philion, J. et al. “Lift, Splat, Shoot: Encoding Driving Scenes.” CVPR, 2020.
- [4] Caesar, H. et al. “nuScenes: A Multimodal Dataset for Autonomous Driving.” CVPR, 2020.
- [5] Yang, Z. et al. “HDMapNet: An Online HD Map Construction and Evaluation Framework.” CVPR, 2021.
- [6] Brown, T. et al. “Language Models are Few-Shot Learners.” NeurIPS, 2020.
These resources offer both foundational and advanced insights, from transformer architectures in vision and language modeling to datasets and methods for autonomous driving scene interpretation.