
What’s new in TensorFlow 2.4?
TF 2.4 is here! With increased support for distributed training and mixed precision, new NumPy frontend and tools for monitoring and diagnosing bottlenecks, this release is all about new features and enhancements for performance and scaling.
New Features in tf.distribute
Parameter Server Strategy
In 2.4, the tf.distribute module introduces experimental support for asynchronous training of models with ParameterServerStrategy and custom training loops. Like MultiWorkerMirroredStrategy, ParameterServerStrategy is a multi-worker data parallelism strategy; however, the gradient updates are asynchronous.
A parameter server training cluster consists of workers and parameter servers. Variables are created on parameter servers and then read and updated by workers during each step. The reading and updating of variables happens independently across the workers without any synchronization. Because the workers do not depend on one another, this strategy has the benefit of worker fault tolerance and is useful if you use preemptible VMs.
To get started with this strategy, check out the Parameter Server Training tutorial. This tutorial shows you how to set up ParameterServerStrategy and define a training step, and explains how to use the ClusterCoordinator class to dispatch the execution of training steps to remote workers.Multi Worker Mirrored Strategy
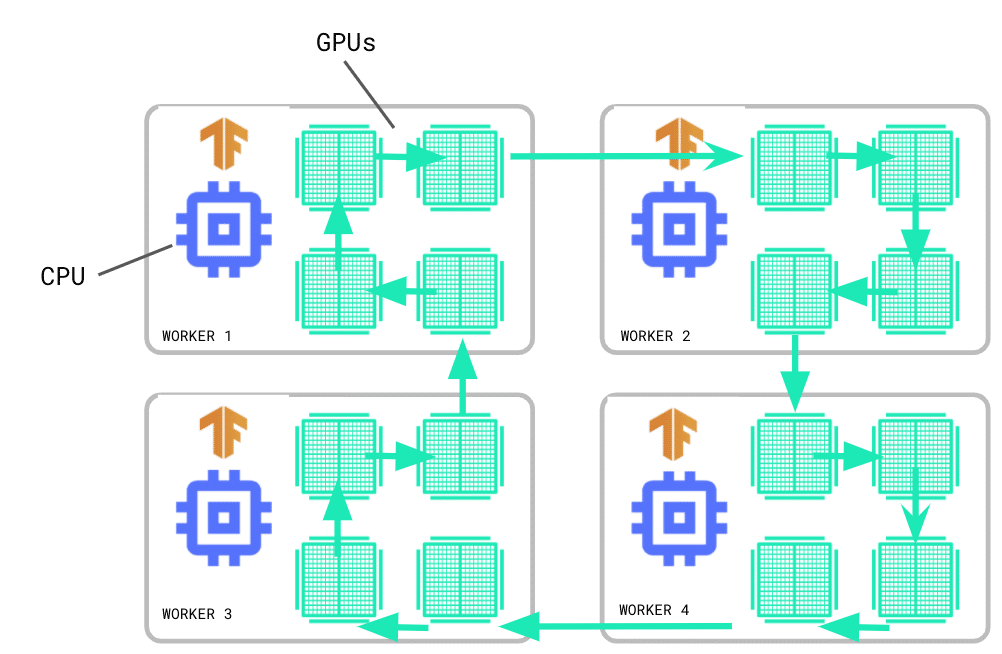
MultiWorkerMirroredStrategy has moved out of experimental and is now part of the stable API. Like its single worker counterpart, MirroredStrategy, MultiWorkerMirroredStrategy implements distributed training with synchronous data parallelism. However, as the name suggests, with MultiWorkerMirroredStrategy you can train across multiple machines, each with potentially multiple GPUs.
In synchronous training, each worker computes the forward and backward passes on different slices of the input data, and the gradients are aggregated before updating the model. For this aggregation, known as an all-reduce, MultiWorkerMirroredStrategy uses CollectiveOps to keep variables in sync. A collective op is a single op in the TensorFlow graph that can automatically choose an all-reduce algorithm in the TensorFlow runtime according to hardware, network topology, and tensor sizes.
To get started with MultiWorkerMirroredStrategy, check out the Multi-worker training with Keras tutorial, which has been updated with details on dataset sharding, saving/loading models trained with a distribution strategy, and failure recovery with the BackupAndRestore callback.
If you are new to distributed training and want to learn how to get started, or you’re interested in distributed training on GCP, see this blog post for an introduction to the key concepts and steps.
Updates in Keras
Mixed Precision
In TensorFlow 2.4, the Keras mixed precision API has moved out of experimental and is now a stable API. Most TensorFlow models use the float32 dtype; however, there are lower-precision types such as float16 that use less memory. Mixed precision is the use of 16-bit and 32-bit floating point types in the same model for faster training. This API can improve model performance by 3x on GPUs and 60% on TPUs.
To make use of the mixed precision API, you must use Keras layers and optimizers, but it’s not necessary to use other Keras classes such as models or losses. If you’re curious to learn how to take advantage of this API for better performance, check out the Mixed Precision tutorial.
Optimizers
This release includes refactoring the tf.keras.optimizers.Optimizer class, enabling users of model.fit or custom training loops to write training code that works with any optimizer.All built-in tf.keras.optimizer.Optimizer subclasses now accept gradient_transformers and gradient_aggregator arguments, allowing you to easily define custom gradient transformations.
With the refactor, you can now pass a loss tensor directly to Optimizer.minimize when writing custom training loops:
tape = tf.GradientTape()
with tape:
y_pred = model(x, training=True)
loss = loss_fn(y_pred, y_true)
# You can pass in the `tf.GradientTape` when using a loss `Tensor` as shown below.
optimizer.minimize(loss, model.trainable_variables, tape=tape)These changes are intended to make both Model.fit and custom training loops more agnostic to optimizer details, allowing you to write training code that works with any optimizer without modification.Functional API model construction internal improvements
Lastly, TensorFlow 2.4 includes a major refactoring of the internals of the Keras Functional API, improving the memory consumption of functional model construction and simplifying triggering logic. This refactoring also ensures TensorFlowOpLayers behave predictably and work with CompositeTensor type signatures.
Introducing tf.experimental.numpy
TensorFlow 2.4 introduces experimental support for a subset of NumPy APIs, available as tf.experimental.numpy. This module enables you to run NumPy code, accelerated by TensorFlow. Because it is built on top of TensorFlow, this API interoperates seamlessly with TensorFlow, allowing access to all of TensorFlow’s APIs and providing optimized execution using compilation and auto-vectorization. For example, TensorFlow ND arrays can interoperate with NumPy functions, and similarly TensorFlow NumPy functions can accept inputs of different types including tf.Tensor and np.ndarray.
import tensorflow.experimental.numpy as tnp
# Use NumPy code in input pipelines
dataset = tf.data.Dataset.from_tensor_slices(
tnp.random.randn(1000, 1024)).map(
lambda z: z.clip(-1,1)).batch(100)
# Compute gradients through NumPy code
def grad(x, wt):
with tf.GradientTape() as tape:
tape.watch(wt)
output = tnp.dot(x, wt)
output = tf.sigmoid(output)
return tape.gradient(tnp.sum(output), wt)You can learn more about how to use this API in the NumPy API on TensorFlow guide.
New Profiler Tools
MultiWorker Support in TensorFlow Profiler
The TensorFlow Profiler is a suite of tools you can use to measure the training performance and resource consumption of your TensorFlow models. The TensorFlow Profiler helps you understand the hardware resource consumption of the ops in your model, diagnose bottlenecks, and ultimately train faster.
Previously, the TensorFlow Profiler supported monitoring multi-GPU, single host training jobs. In 2.4 you can now profile MultiWorkerMirroredStrategy training jobs. For example, you can use the sampling mode API to perform on demand profiling and connect to the same server:port in use by MultiWorkerMirroredStrategy workers:
# Start a profiler server before your model runs.
tf.profiler.experimental.server.start(6009)
# Model code goes here....
# E.g. your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you
# would like to profile for a duration of 2 seconds. The profiling data will
# be saved to the Google Cloud Storage path “your_tb_logdir”.
tf.profiler.experimental.client.trace(
'grpc://10.0.0.2:6009,grpc://10.0.0.3:6009,grpc://10.0.0.4:6009',
'gs://your_tb_logdir',
2000)Alternatively, you can use the TensorBoard profile plugin by providing the worker addresses to the Capture Profile tool.
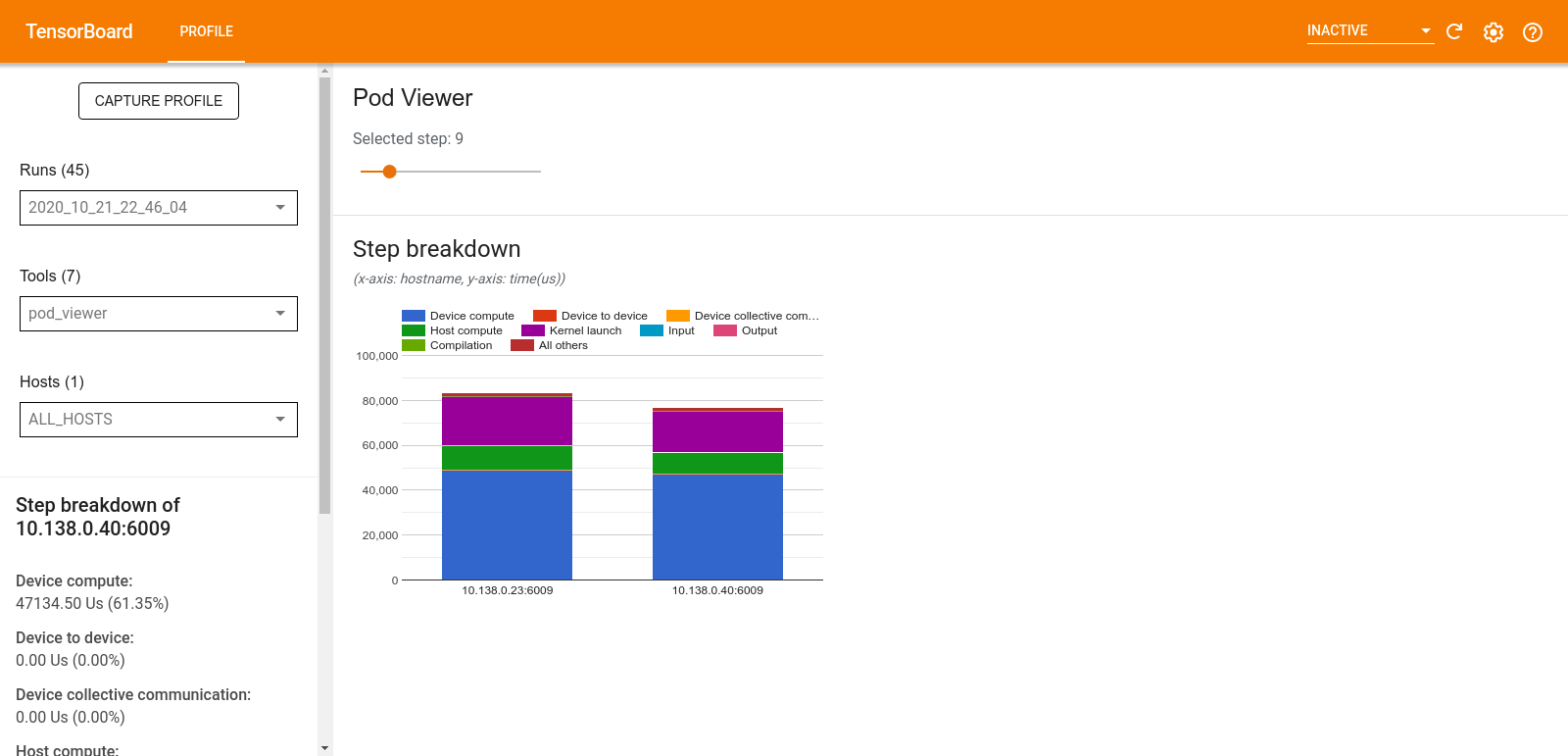
After profiling, you can use the new Pod Viewer tool to choose a training step and view its step-time category breakdown across all workers.
For more information on how to use the TensorFlow Profiler, check out the newly released GPU Performance Guide. This guide shows common scenarios you might encounter when you profile your model training job and provides a debugging workflow to help you get better performance, whether you’re training with one GPU, multiple GPUs, or multiple machines.TFLite Profiler
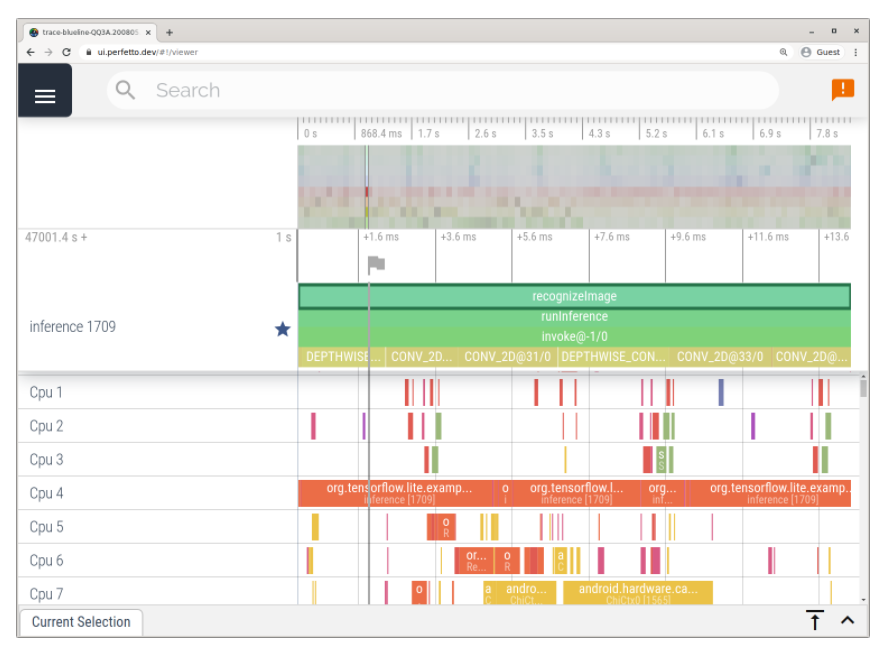
The TFLite Profiler enables tracing TFLite internals in Android to identify performance bottlenecks. The TFLite Performance Measurement Guide shows you how to add trace events, enable TFLite tracing, and capture traces with both the Android Studio CPU Profiler and the System Tracing app.
Example trace using the Android System Tracing app
New Features for GPU Support
TensorFlow 2.4 runs with CUDA 11 and cuDNN 8, enabling support for the newly available NVIDIA Ampere GPU architecture. To learn more about CUDA 11 features, check out this NVIDIA developer blog.
Additionally, support for TensorFloat-32 on Ampere-based GPUs is enabled by default. TensorFloat-32, or `TF32` for short, is a math mode for NVIDIA Ampere GPUs that causes certain float32 ops, such as matrix multiplications and convolutions, to run much faster on Ampere GPUs but with reduced precision. To learn more , see the documentation for tf.config.experimental.enable_tensor_float_32_execution.


