
ZFS dRAID: Expanding the Storage Endurance Envelope for Large Installations
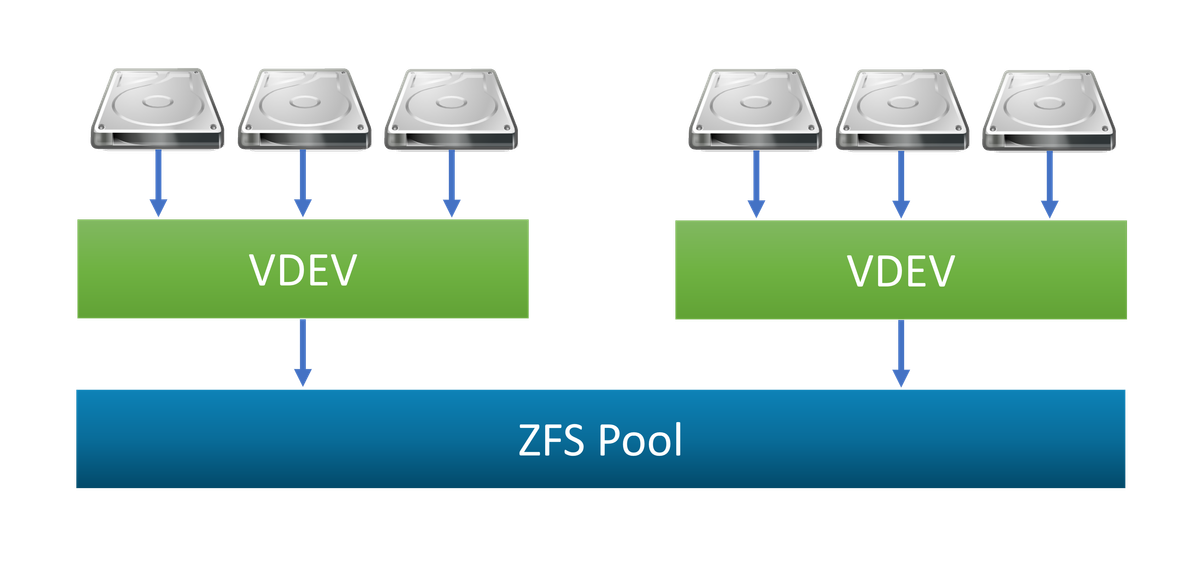
Avoiding the Death Spiral
Wide RAID stripes are often used by administrators to maximise usable storage for a number of spindles. For a number of reasons, RAID-Z deployments with large strip widths, ten or larger, are subject to low resilver performance. Resilvering a full vdev means reading from any healthy disc and writing to the new spare continuously. This will saturate the replacement disc with writes over the rest of the vdev while scattering searches. Reconstruction can take weeks for 14 broad RAID-Z2 vdevs using 12TB spindles. When the system has not been idle for a minimum period, Resilver I/O activity is deprioritized. In order to recalculate data during reslivering, full zpools get fragmented and require additional I/Os. A pool can degenerate into a never-ending cycle of Aka pool reconstruction or loss: the Death Spiral.
Disks can fail in groups as spindles age together, as defect counts and mechanical failure are not independent random processes with regard to age. This math is further complicated by SSD as the wear levelling stamina will be very closely matched and device clusters under the same load may fail together. The mean time given by the manufacturer for failure is a forward-looking statement and is not suitable for planning replenishment. One manufacturer claims an MTBF of 1.2 million hours: a dubious commitment to quality for 137 years. It is poor planning to assume that any drive will not be selected today to fail dramatically.
DRAID is an option for quick parity rebuilding that can mitigate the death spiral behaviour of wide RAIDZ stripes, but does not encourage wide stripes, as reflected in its default width setting of eight. Dedicating sufficient parity increases the durability of the ZFS pool and the risk of losing the pool should be informed of the investment in parity.
Distributed Spares?
Spare discs are a way to keep a disc warm and ready for a failed member to be replaced. Usually, until they are scrammed into action during a rebuild, the life of a spare is leisurely idle. That idleness is a lost opportunity for useful work to be done. A dRAID does not contain any specific spare discs. Instead, enough blocks are distributed throughout the vdev to function as spares. A clever redistribution of work so that all discs are always in use is the distributed spare. A disc failure causes that dedicated space to be rebuilt. The vdev can be re-balanced to return the spare block after replacement discs are available and put the replacement disc in for use.
Fixed Stripe Width
A whole stripe in dRAID is allocated at once, unlike RAID-Z, no matter how many disc blocks are needed to store the object. The width of the strip is defined by the size of the disc sector multiplied by the number of data drives in the RAID group.
RAID-Z has a block layout optimization method for minimising block allocations for small files. However, dRAID prioritises the speed of rebuilding parity and does not make the same attempt to preserve space. DRAID will not be able to use all the disc blocks fully if your files are a small fraction of the stripe size. For example, dRAID vdev has a default stripe of 32k (4k per disc, 8 discs); at least 32k will be required for any allocation. Internal padding is assigned after the request object is stored to fill out the stripe width. It will suit smaller allocations and improve drive utilisation by using a smaller stripe width or providing a special mirror vdev.
A Story of Two Resilvers
After a failure, the real or distributed spare is written in sequence to rebuild the drive according to parity data, following only the parity layout in the space map. By issuing large I/O blocks, reducing searches, and preventing tree indirection overhead, sequential reconstruction can be achieved quickly. The contents of the rebuilt disc are not necessarily consistent with the Merkle tree that proves that the data in zpools is intact. This bitwise copy of the disc must first be reconstructed, enabling the system to return to its mostly intact state and return to service. That is to say, the process of sequential reconstruction restores the pool redundancy level, but without being able to verify the data checksums. The benefit of this is that it can be completed much faster, reducing the window during which the pool could be put at risk by additional disc failures.
After a sequential resilver, a healing resilver is triggered automatically, it is a final operation that verifies that all the contents of the drives through block pointer traversal match their initial checksums. In order to quickly find and reconstruct writes to the failed disc, the healing resilver has a number of optimizations. The rebalance operation is another sequential resilver, followed by a healing resilver, if a replacement drive can be added to the pool.
A scrub is the gold standard for the health of a pool; however, visiting each block allocated in the pool could be a prohibitive amount of work. In an environment where failures need to be routinely repaired, the healing resilver allows a practical return to operation.
OpenZFS 2.1 will support dRAID in early 2021, according to a report from the January OpenZFS leadership meeting. If you need it now, build the OpenZFS head branch against newly supported operating systems: FreeBSD 12.1+, Linux 5.10+, Illumos, NetBSD et al. A good indication that dRAID fulfils the ZFS data protection commitment is the OpenZFS regression test suite ztest. For more than ten years, corporate clients at IBM and Panasas have been flogging other distributed RAID systems. It is a mature idea that complements the set of ZFS tools.
Quick Start
There is no better way to learn software than to run headlong into mistakes.
We’ll install ZFS head from source and gin up some ‘md’ file backed disks.
‘zpool create r2dRAID dRAID2:3d:1s:14c /dev/md1 /dev/md2 …. /dev/md13 /dev/md14’
There it is, a zpool with a dRAID vdev, ready to go to work.
The OpenZFS wiki has a good description of dRAID care, resilvering and rebalancing
Following the life cycle of failure and replacement in the documentation is recommended before those skills are tested in production.
dRAID Nomenclature
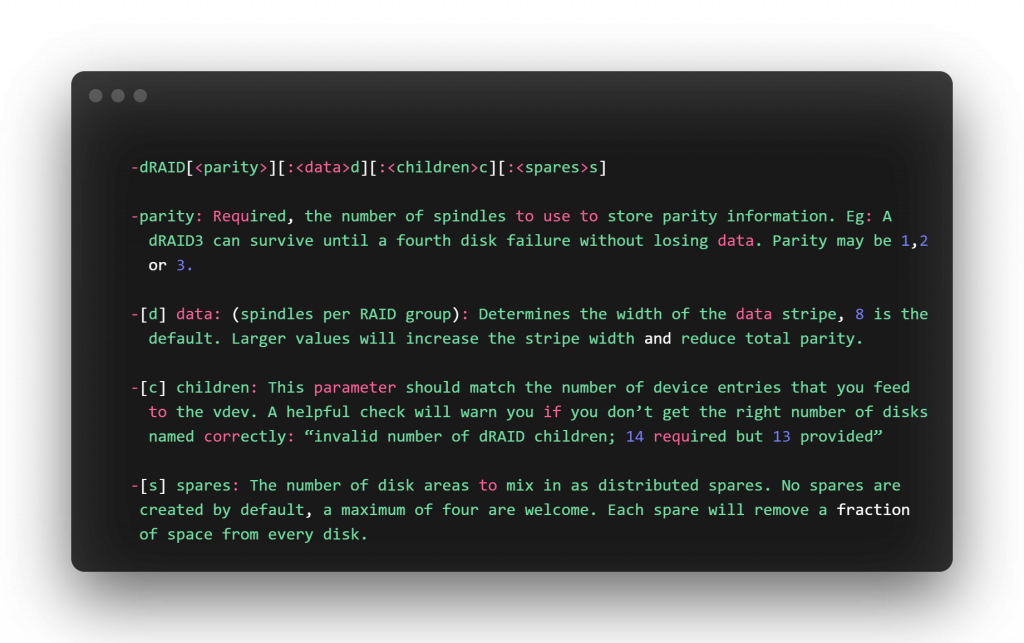
Let’s decode the nomenclature that describes the geometry of a dRAID vdev. A string such as “dRAID2:3d:14c:1s” encodes the following about a dRAID vdev.
-dRAID[<parity>][:<data>d][:<children>c][:<spares>s]
-parity: Required, the number of spindles to use to store parity information. Eg: A dRAID3 can survive until a fourth disk failure without losing data. Parity may be 1,2 or 3.
-[d] data: (spindles per RAID group): Determines the width of the data stripe, 8 is the default. Larger values will increase the stripe width and reduce total parity.
-[c] children: This parameter should match the number of device entries that you feed to the vdev. A helpful check will warn you if you don’t get the right number of disks named correctly: “invalid number of dRAID children; 14 required but 13 provided”
-[s] spares: The number of disk areas to mix in as distributed spares. No spares are created by default, a maximum of four are welcome. Each spare will remove a fraction of space from every disk.
Parting Short
The dRAID offers a solution for large arrays, vdevs with fewer than 20 spindles will have limited benefits from the new option. The performance and resilver result will be similar to RAIDZ for small numbers of spindles. Installations with many spindles will see the best results with regards to performance, fast spare activation and replacement. The benefits come with the associated cost of whole stripe at a time allocation for small objects in the pool. This overhead should be calculated in the design of the pool before it’s an operational surprise.
There is no free lunch with dRAID for in saving parity or spare drives, they are your defense against data loss. As drives increase in size, their time to resilver increases and the amount of data they can destroy increases.


